










Россия
Россия
Рассмотрен вопрос качества аудиосигнала во время проведения видеоконференций. Описано влияние шумов на качество и разборчивость речевого сигнала. Проведен анализ процесса шумоподавления в аудиосигнале в реальном времени. Выделены основные проблемы, возникающие при цифровой обработке аудиосигнала в реальном времени. Рассмотрены основные методы шумоподавления и выявлены недостатки классических методов. Сформулирована проблема устранения шумов с переменной полосой частот классическими методами шумоподавления. Обоснована необходимость создания гибридной методики шумоподавления с использованием методов машинного и глубокого обучения для устранения как статичных шумов, так и шумов со сложной и переменной спектральной характеристикой. Выделены основные подходы к решению задачи шумоподавления в реальном времени, а именно подход с распознаванием и устранением шумов и подход с распознаванием голоса и устранением звуков, отличающихся от речевого сигнала. Описан алгоритм шумоподавления на основе подхода с распознаванием и устранением шумов. Предложена оптимизация алгоритма путем разложения спектра входного сигнала согласно шкале Барка. Предложена рекуррентная нейронная сеть в качестве инструмента для реализации алгоритма шумоподавления. Определены форматы входных и выходных данных нейронной сети, а также формат обучающих данных. Описана модель корректировки параметров и правил для возможности адаптации алгоритма шумоподавления к специфичным условиям эксплуатации. Предложена гибридная методика шумоподавления, комбинирующая классические методы шумоподавления и методы, основанные на рекуррентной нейронной сети. Разработана схема гибридной методики. Предложен способ тестирования эффективности методики шумоподавления.
видеоконференция, речевой сигнал, шумоподавление, качество сигнала, спектр, фильтрующий коэффициент, шумовой порог, полоса частот, шкала Барка, рекуррентные нейронные сети
Введение
В современном мире с развитием цифровизации и в связи с ограничениями, возникшими из-за недавней короновирусной пандемии и последовавшей за ней самоизоляции, видеоконференцсвязь стала востребованным решением на современном рынке технологий [1, 2]. Однако во время проведения видеоконференций нередко возникают проблемы с качеством аудиосигнала, исходящего от участников. Речевой сигнал – основной путь передачи информации при естественном общении между людьми. Все звуки, не являющиеся человеческой речью, могут быть отнесены к категории шума. Качество воспроизведения важно для любого слушателя: наличие в звуке шумов, которые не имеют отношения к содержанию, такие как помехи, стуки, шипение, электрические щелчки и трески, гул и т. д., мешают восприятию звуковой информации. Сильные шумы и искажения способны не только ухудшить качество воспринимаемых сигналов, но и привести к снижению разборчивости речи [3, 4].
Шумоподавление – это процесс устранения шумов из сигнала с целью повышения его качества [5]. В настоящее время существует множество методов шумоподавления, которые избирательно меняют форму сигнала, т. е. амплитудно-частотную характеристику (АЧХ) [6]. Первые научные работы, описывающие алгоритмы шумоподавления, были опубликованы еще в 70-х гг. XX в. [7]. Наиболее распространенный метод шумоподавления – фильтр нижних (или высоких) частот. Данный метод заключается в проектировании фильтра на основе спектральной характеристики шума и удаления шума путем исключения из выходного аудиосигнала частотного диапазона, соответствующего шуму. Данный метод имеет низкую эффективность, поскольку фильтр не является избирательным, т. е. он не различает сигнал и шум в пределах заданного диапазона частот, и, соответственно, шум со сложной и переменной спектральной характеристикой не будет подавлен [5, 6]. Существует и более сложный метод шумоподавления – спектральное вычитание, – который является улучшенной версией фильтра нижних (или высоких) частот. Основная его идея заключается в том, что анализируется сегмент аудиосигнала, в котором присутствует только шум, и выделяется спектр шума и помех, а затем из выходного сигнала с речью вычитается полученный спектр шума. Данный способ подойдет для устранения сложного, т. е. не лежащего в одной узкой полосе частот, но статичного шума [7]. Также известным и часто используемым методом шумоподавления является метод шумового порога (затвора). Он применим в том случае, если уровень громкости речевого сигнала значительно выше громкости нежелательного шума. Шумовой порог позволяет проходить входному сигналу в выходной только в том случае, если уровень громкости входного сигнала выше установленного порога [5, 6].
Поскольку процесс шумоподавления рассматривается в условиях его применения в системе видеоконференций, этот процесс осложняется тем, что сигнал необходимо обрабатывать в реальном времени без возможности полноценного анализа спектра входящего аудиосигнала. В таком случае допустимы задержки только в несколько десятков миллисекунд, за которые необходимо проводить анализ и обработку аудиосигнала [8]. Чаще всего полоса шумовых частот переменна, т. е. в аудиосигнал могут попадать различные шумы и иные нежелательные звуки, которые не были предусмотрены цифровым фильтром. Для решения данной проблемы существуют алгоритмы шумоподавления, основанные на использовании методов машинного и глубокого обучения, позволяющие анализировать спектр аудиосигнала в реальном времени [8–10].
Несмотря на наличие различных способов шумоподавления, по-прежнему наблюдается потребность в создании новых и в усовершенствовании существующих методов, поскольку некоторые из них, улучшая разборчивость речевого сигнала, могут снижать его качество. Также для некоторых методов характерны различные артефакты, осложняющие восприятие информации [4, 11].
Шумоподавление в речевом сигнале в реальном времени
При решении задачи шумоподавления в реальном времени можно выделить концептуально разные подходы:
– алгоритм анализирует спектр входящего аудиосигнала и при обнаружении шума исключает из выходного аудиосигнала найденный шум;
– алгоритм анализирует спектр входящего аудиосигнала и при обнаружении голоса (речевой сигнал) исключает все остальные звуки, не совпадающие с этим голосом.
Оба подхода имеют свои преимущества и недостатки. Например, подход с обнаружением голоса менее универсален, поскольку потребует дополнительного (и, возможно, длительного) обучения новому образцу голоса говорящего, но может давать более качественный результат, поскольку алгоритм будет устранять шумы, которые им изначально не были предусмотрены, при условии корректного определения голоса говорящего.
Наилучших результатов можно добиться, комбинируя оба подхода.
Для реализации первого и, при небольших изменениях, второго подхода алгоритм шумоподавления должен иметь различные векторы коэффициентов для различных типов шумов (или иметь правила для их вычисления), которые характеризуются спектром шума, а также иметь модуль, определяющий, какой тип шума присутствует в данный момент в аудиосигнале и какой вектор фильтрующих коэффициентов необходимо применить (рис. 1).
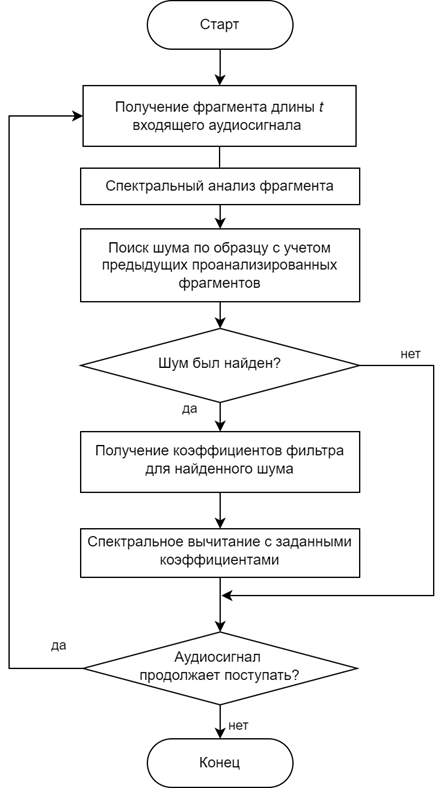
Рис. 1. Упрощенная блок-схема алгоритма шумоподавления на основе обнаружения шумов
Fig. 1. Simplified flowchart of noise reduction algorithm based on noise detection
Представленный на рис. 1 алгоритм шумоподавления можно реализовать с использованием методов машинного обучения, а именно с применением рекуррентной нейронной сети (РНС), которая подходит в данном случае лучше, чем классический многослойный перцептрон, поскольку данная сеть позволяет анализировать временные последовательности [8, 9]. Очевидно, что из первых нескольких миллисекунд аудиосигнала (например, 10 см) достаточно сложно определить, частью какого звука является данный фрагмент, не говоря уже о точном определении типа шума.
Модуль алгоритма должен вычислять начальную вероятностную оценку о принадлежности звука к тому или иному типу шума, и с каждым последующим временным интервалом уточнять оценку с поступлением новой информации.
Необходимо уточнить, что реализация на РНС может выглядеть немного иначе, чем это изображено на блок-схеме алгоритма выше, т. е. РНС может
не осуществлять непосредственный поиск по образцу из базы данных с образцами, а вычислять коэффициенты фильтра на основе внутренних для сети закономерностей, паттернов и критериев шумов, которые были получены с помощью обучающих данных вида X (зашумленный сигнал) – Y (чистый сигнал).
Чтобы алгоритм мог выполняться на большем количестве пользовательских вычислительных устройств, таких как персональные компьютеры
и мобильные устройства [12], необходимо уменьшить вычислительную сложность алгоритма и, соответственно, количество узлов в РНС, разбив спектр аудиосигнала на полосы частот в соответствии со шкалой Барка (24 полосы), которая является неравномерной психоакустической шкалой, связанной с критическими полосами слуха [13, 14]. При таком упрощении алгоритм будет работать с 24 фильтрующими коэффициентами, покрывающими диапазон от 0 Гц до 20 кГц.
В соответствии с алгоритмом, описанным выше, процесс шумоподавления можно выразить формулой
где y (b, t) – выходная амплитуда звука, дБ, на полосе частот b в момент времени t, мс; kn (b, t) – коэффициент фильтра в диапазоне [0; 1], соответствующий образцу шума n на полосе частот b в момент времени t; b – номер полосы частот от 1 до 24 в соответствии со шкалой Барка; x (b, t) – входная амплитуда звука, дБ, на полосе частот b в момент времени t.
Модель корректировки параметров и правил алгоритма шумоподавления
Может возникнуть ситуация, когда фильтр будет некорректно работать в некоторых специфичных условиях вследствие того, что обучающий набор данных не включает в себя все возможные шумы. Помимо этого, поскольку записывающие устройства конечных пользователей имеют различные характеристики, спектральные данные шумов могут отличаться, что также может негативно повлиять на эффективность работы алгоритма шумоподавления.
Необходим механизм, позволяющий вносить корректировки в работу алгоритма. Для возможности адаптации алгоритма шумоподавления к специфичным условиям эксплуатации системы предлагается следующая модель корректировки параметров и правил:
где M – модель корректировки параметров и правил для алгоритма шумоподавления; A – фрагмент входного аудиосигнала, в котором содержатся только шумы, которые следует устранить из аудиосигнала (сегмент шума); Po – текущий набор параметров и правил для шумоподавления (матрица весов); t – длительность сегмента шума; Pn – новый набор параметров и правил для шумоподавления, полученный в процессе работы алгоритма.
Гибридная методика шумоподавления
Для эффективного устранения шумов предлагается следующая методика шумоподавления (рис. 2).
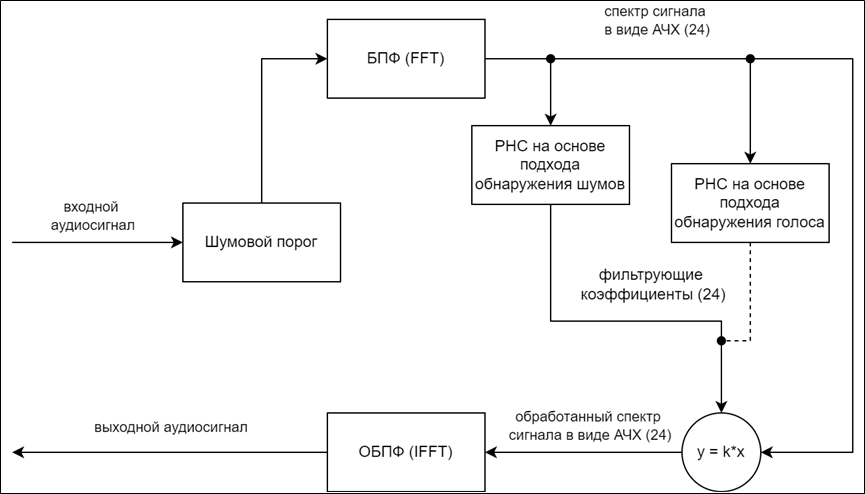
Рис. 2. Схема гибридной методики шумоподавления:
БПФ – быстрое преобразование Фурье; ОБПФ – обратное быстрое преобразование Фурье
Fig. 2. Diagram of hybrid noise reduction technique:
FFT – Fast Fourier Transform; IFFT – Inverse Fast Fourier Transform
Текстовое описание методики, которая изображена на схеме:
1. Отсеивание шумов, громкость которых ниже громкости речевого сигнала, на основе метода шумового порога.
2. Представление спектра входящего аудиосигнала в виде массива АЧХ (24 элемента) в соответствии со шкалой Барка с помощью алгоритма быстрого преобразования Фурье (БПФ, FFT) [6].
3. Применение РНС, основанной на подходе с обнаружением шумов, и вычисление массива
(24 элемента) фильтрующих коэффициентов со значениями, лежащими в диапазоне [0; 1].
4. Применение РНС, основанной на подходе с обнаружением голоса, и вычисление фильтрующих коэффициентов в том случае, если на предыдущем этапе фильтрующие коэффициенты никак не воздействуют на аудиосигнал (т. е. равны единице).
5. Изменение формы (АЧХ) аудиосигнала за счет использования фильтрующих коэффициентов в соответствии с формулой (1).
6. Получение выходного аудиосигнала с помощью алгоритма обратного быстрого преобразования Фурье (ОБПФ, IFFT).
Проиллюстрировать ожидаемый результат работы гибридной методики шумоподавления можно с помощью следующей спектрограммы (рис. 3).
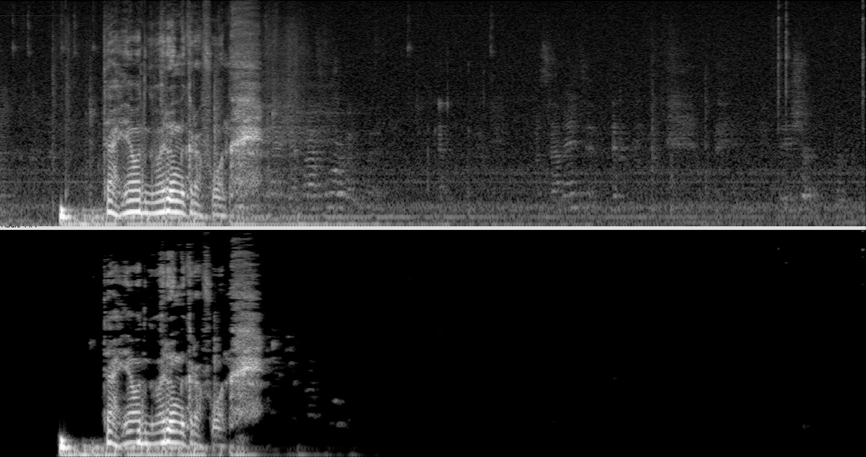
Рис. 3. Спектрограмма зашумленного (сверху) и обработанного (снизу) мужского голоса
Fig. 3. Spectrogram of noisy (upper) and processed (lower) male voice
Тестирование эффективности методики следует проводить с использованием методов оценки качества речевого сигнала: MOS (метод экспертных оценок) [15, 16], SNR (отношение сигнал/шум) [17], PESQ (объективный метод определения качества речи) [18, 19]. Если в результате тестирования выявлены неудовлетворительные результаты, необходимо скорректировать параметры алгоритма шумоподавления с использованием модели (1).
Заключение
Разработана гибридная методика шумоподавления в реальном времени. Данная методика отличается сочетанием классического метода шумового порога и двух алгоритмов (третий и четвертый блоки на схеме методики, т. е. два алгоритма на РНС с разными подходами) шумоподавления, основанных на рекуррентной нейронной сети. Один из алгоритмов соответствует подходу с распознаванием шума и исключению его из выходного сигнала, а другой (основанный на распознавании голоса – подходу с распознаванием голоса и исключению всех остальных звуков. Для возможности адаптации алгоритма шумоподавления к новым условиям эксплуатации в методике предусмотрена соответствующая модель корректировки параметров и правил шумоподавления. Следующим шагом по решению задачи шумоподавления в реальном времени является программная реализация модуля шумоподавления для системы видеоконференций согласно предложенной методике. Для этого необходимо детализировать структуру рекуррентной нейронной сети, реализующую описанный алгоритм шумоподавления, и реализовать модель сети в виде программы. После этого необходимо обучить модель на большом объеме данных и провести тестирование эффективности шумоподавления.
1. Рудых Л. Г. Дистанционное обучение в вузе: проблемы и перспективы // Молодеж. вестн. ИрГТУ. 2020. Т. 10. № 2. С. 158-162.
2. Демина Н. В., Сабанова Л. В., Сабанова В. А. Видеоконференции и дистанционное обучение как основные виды телемедицинских услуг // Науч.-метод. электрон. журн. «Концепт». 2019. № V2. С. 28-33.
3. Бысько М. В. Шумология // Медиамузыка. 2014. № 3. С. 6.
4. Топников А. И. Оценка разборчивости и обработка речевых сигналов в задаче шумоподавления: автореф. дис. … канд. техн. наук. Владимир, 2012. 16 с.
5. Шкритек П. Справочное руководство по звуковой схемотехнике / пер. с нем. М.: Мир, 1991. 446 с.
6. Айфичер Э., Джервис Б. Цифровая обработка сигналов: практический подход / пер. с англ. М.: Вильямс, 2017. 992 с.
7. Boll S. F. Suppression of acoustic noise in speech using spectral subtraction // IEEE Transactions On Acoustics, Speech, And Signal Processing. 1979. V. Assp-27. N. 2. URL: https://ieeexplore.ieee.org/document/1163209 (дата обращения: 23.10.2022).
8. Valin J.-M. A Hybrid DSP/Deep Learning Approach to Real-Time Full-Band Speech Enhancement // Mozilla Corporation Mountain View, CA, USA, 2018. URL: https://jmvalin.ca/papers/rnnoise_mmsp2018.pdf (дата обращения: 23.10.2022).
9. Yong Xu, Jun Du, Li-Rong Dai, Chin-Hui Lee. A Regression Approach to Speech Enhancement Based on Deep Neural Networks // IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2015. V. 23. Iss. 1. P. 7-9. URL: https://ieeexplore.ieee.org/document/6932438 (дата обращения: 18.11.2022).
10. Дубенко Ю. В., Дышкант Е. Е. Нейросетевой алгоритм выбора методов для прогнозирования временных рядов // Вестн. Астрахан. гос. техн. ун-та. Сер.: Управление, вычислительная техника и информатика. 2019. № 1. С. 51-60.
11. Афанасьев А. А. Модели и методы анализа и обработки речевого сигнала в системах связи: автореф. дис. … д-ра техн. наук. Орел, 2018. 16 с.
12. Савельев А. И. Архитектуры, алгоритмы и программные средства обработки потоков многомодальных данных в пиринговых веб-приложениях видеоконференцсвязи: автореф. дис. … канд. техн. наук. СПб., 2016. 17 с.
13. Zwicker E. Subdivision of the Audible Frequency Range into Critical Bands // The Journal of the Acoustical Society of America. 1961. № 33 (2). P. 248.
14. RFC 6716: Definition of the Opus Audio Codec // RFC Editor. URL: https://www.rfc-editor.org/rfc/rfc6716 (дата обращения: 16.11.2022).
15. Recommendation ITU-T P.800 (1996). Methods for subjective determination of transmission quality // ITU-T Recommendations. URL: https://www.itu.int/rec/T-REC-P.800-199608-I (дата обращения: 23.10.2022).
16. Полторак В. П., Моргаль О. М., Заика Ю. А. Оценка качества передачи речи в IP-телефонии // Молодой ученый. 2014. № 4 (63). С. 121-123.
17. Топников А. И., Нестеров М. С., Новоселов С. А., Приоров А. Л. Неэталонная оценка разборчивости зашумленных речевых сигналов // Цифровая обработка сигналов. 2015. № 1. С. 39-44.
18. Recommendation ITU-T P.862 (2001). Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs // ITU-T Recommendations. URL: https://www.itu.int/rec/T-REC-P.862-200102-I (дата обращения: 23.10.2022).
19. Берко Г. А., Галич С. А., Пасюк А. О., Семенов Е. С. Применение алгоритма PESQ для оценки качества передачи речи по IP-сетям // Огарев-online. 2015. № 11 (52). С. 3.
