











Astrakhan, Russian Federation
Russian Federation
Astrakhan, Russian Federation
. In the context of recognition of digitized images with low quality due to the presence of various noises, a model of the character recognition process is proposed that allows taking into account the different quality of the input images. The problem of recognizing images containing different types of noise is solved. Algorithms that smooth the image and remove dense accumulation of noise often do not cope with noise scattered evenly throughout the image (“salt”), and the use of several noise suppression algorithms at once can affect the image quality. If you choose the wrong blurring algorithm, you can subsequently get less accurate coordinates of the image contours for further segmentation and recognition when searching for boundaries. When segmenting an image, it may happen that due to incorrect processing, the process of searching for character pixels will lead to an incorrect result. To solve this problem, it is proposed to form a set of blurring algorithms and a set of binarization algorithms. At the stage of image processing, using multiple combinations instead of one specific combination of algorithms will help to achieve a more flexible and resistant operation of the recognition module to various types of defects in images. The developed model of the character recognition process will help to achieve a significant increase in the accuracy of recognition of unciphered documents due to the most efficient processing of images with different noise. In addition to removing noise, the improved model will allow to more accurately find the boundaries of images that have quality problems. The theoretical significance of the study is the result of modeling the character recognition process using many combinations of image processing algorithms to conduct a more extensive analysis and identify the most effective combinations of algorithms.
image processing, character recognition, image digitization, image noise, binarization, blurring, smoothing, neural network, sets 51
Введение
Статистика национального проекта «Малое и среднее предпринимательство» на 2022 г. демонстрирует, что количество субъектов малого и среднего предпринимательства выросло на 2,1 % по сравнению с 2021 г., однако количество работников уменьшилось на 0,5 %, т. е. количество субъектов медленно растет, а количество работников в таких организациях только уменьшается [1].
На различных предприятиях малого и среднего бизнеса документоведы получают больше 100 писем в месяц в неоцифрованном формате PDF без текстового слоя, на которые нужно отвечать. При необходимости заимствования информации из таких документов возникает проблема невозможности копирования текста. Без наличия качественной системы OCR не получится за короткий срок сформировать новый документ или изъять какую-либо информацию из полученного документа. На процесс формирования нового оцифрованного документа затрачивается очень много времени, что может отразиться на производительности таких организаций. Не все организации малого и среднего предпринимательства могут позволить себе высокоточные системы распознавания: затраты на внедрение таких систем могут быть неподъемным грузом для таких организаций. В некоторых случаях необходимо затрачивать средства на технику, которая будет поддерживать систему распознавания, на обучение персонала и на саму систему. Одни качественные системы ушли с рынка в России, другие из-за ряда проблем предлагают функционал с низким процентом распознавания проблемных документов.
Программы, реализующие рассматриваемый процесс, уже существуют, однако у каждой из них есть серьезные недостатки. Например, OCRFeeder – программа с открытым исходным кодом для операционной системы Linux – давно не сопровождается. Другие, более популярные программы, такие как FineReader, ушли с рынка в РФ и Белоруссии. Системы от 1С или Smart Engines распознают только структурированные документы, что не является гибким решением. Если рассматривать облачные аналоги, то появляется угроза информационной безопасности. В организациях, как правило, очень много важных документов/договоров, которые не должны распространяться [2].
Таким образом, актуальной становится задача разработки модели процесса распознавания символов, которая учитывает входные изображения различного качества.
Проблемы текущих решений
Многие системы OCR, доступные для малого бизнеса, имеют низкую точность распознавания. Это связано с многими факторами. Например, алгоритмы обработки изображения не охватывают всевозможные входные изображения разного качества. Для рассмотрения проблемы детальнее можно представить простую OCR-систему, этап сглаживания изображения которой включает в себя только алгоритм медианного размытия. В таком случае при обработке изображения, на котором расположен так называемый гауссовский шум, качество не улучшится, т. к. нужный шум не будет удален. Аналогичные проблемы могут присутствовать и в других алгоритмах, а также в других системах с другим сочетанием алгоритмов. Так, например, одна система может распознать входной документ с точностью в 40 %, а вторая система с другим сочетанием алгоритмов – в 80 %. Однако если загрузить уже другое изображение с другим качеством, результат может быть противоположным, в зависимости от подходящего сочетания алгоритмов. Некоторые системы включают в себя большое количество алгоритмов в одном сочетании, чтобы охватить все возможные исходы. В таком случае скорость этапа обработки изображения может быть низкой, а также использование несовместимых алгоритмов обработки изображения может привести к потере качества.
В научной работе [3] авторы указывают, что обработка изображений с целью их распознавания является одной из центральных и практически важных задач при создании систем искусственного интеллекта. Если после этапа обработки качество изображения осталось или стало низким, то дальнейшие этапы не смогут справиться с задачей в полном объеме. Этап сегментации не сможет разделить изображение на строки, слова и символы, если используется конкретный алгоритм сегментации, а этап с распознаванием – не распознает текст. Самым главным показателем при распознавании текста является точность распознавания. Проанализировав работу И. А. Маслова [4], удалось выяснить, что точность распознавания в значительной степени зависит от качества захваченного изображения и что при распознавании картинок низкого качества допускается множество ошибок [3]. Исходя из вышесказанного, проблема низкой точности распознавания символов может зависеть от качества входного изображения и от этапа обработки изображения, который должен увеличить качество входного изображения за счет алгоритмов обработки.
Согласно исследованиям [5], качество входных изображений зависит от наличия на них шумов, размытости, низкой контрастности или повышенной яркости. На этапе сегментации при остатке шума на изображении после его обработки может возникнуть проблема плохого разделения изображения на строки, слова или символы из-за того, что алгоритм не смог различить шум (пиксели, не относящиеся к тексту) и текст. Чтобы не допустить ошибки в работе алгоритмов на последующих этапах (сегментация, распознавание), на первом этапе необходимо обработать изображения алгоритмами, исключив всевозможные шумы, перепады яркости и т. д.
В работе [6] рассматривается идея использовать не один, а множество фильтров для обработки изображений. По результатам работы был выявлен фильтр, наиболее эффективно обрабатывающий изображение, а также несколько пар фильтров, обработка которыми также позволяла повысить качество распознавания. Однако при использовании в связке алгоритмы обработки, которые сглаживают изображения, например медианное размытие и размытие по Гауссу, можно столкнуться со снижением качества картинок за счет потери важных пикселей, путем многократного размытия.
Многие существующие доступные решения основываются на распознавании негибкими алгоритмами. Такие алгоритмы эффективно работают с определенными документами, шаблонами, шрифтами или языками. Больший процент распознавания может быть достигнут с использованием нейронных сетей, однако в большей степени результат зависит от обучающей выборки.
Моделирование процесса распознавания символов
В формализованном виде процесс распознавания можно представить в виде обобщенной модели (рис. 1):
M: = <X, Y, F>, (1)
где M – модель процесса распознавания; X: = <Ii, Lsample, Tc, Tw, Ttxt> – множество входных параметров, Ii – множество входных неоцифрованных документов, Lsample: = <Ilearn, Alearn> – кортеж данных для обучения нейронной сети, где Ilearn – множество изображений символов для обучения, Alearn – множество символов на изображении (ответы для обучения), Tc: = <Ic, Ac> – кортеж данных для тестирования модуля (символы), где Ic – множество изображений символов, Ac – множество символов на изображениях (ответы для тестирования), Tw: = <Iw, Aw> – кортеж данных для тестирования модуля (слова), где Iw – множество изображений слов, Aw – множество слов на изображениях (ответы), Ttxt: = <Itxt, Atxt> – кортеж данных для тестирования модуля (текст), где Itxt – множество изображений текста, Atxt – множество текстов на изображениях (ответы); Y: = <txt, Reslearn> – множество выходных параметров, где txt – выходной текстовый набор; Reslearn – результат обучения нейронной сети; F: = <Fproc, Fsegm, Frec> – множество механизмов преобразования входного документа, где Fproc – сочетание алгоритмов обработки; Fsegm – алгоритм сегментации, Frec – алгоритм распознавания.
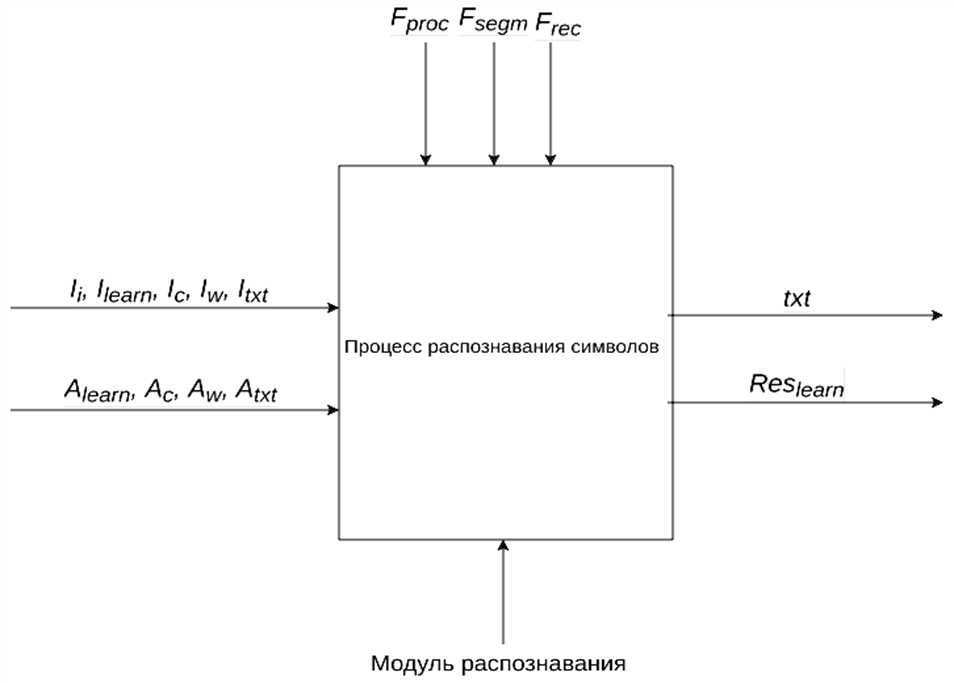
Рис. 1. Обобщенная формализация процесса распознавания
Fig. 1. Generalized formalization of the recognition process
В процесс распознавания входят алгоритмы обработки изображения, сегментации и распознавания [7].
Первый этап в распознавании символов – обработка изображения.
Процесс обработки изображения может проходить различным набором методов, позволяющих повысить эффективность распознавания текста. Основными методами предварительной обработки изображения являются [8]:
– выравнивание изображения;
– размытие изображения [9];
– бинаризация;
– удаление лишних линий.
Благодаря такому набору методов изображение можно подготовить для дальнейшего этапа сегментации [10].
Второй этап – сегментация [11]. В данном случае сегментация необходима для поиска нужных областей текста. Разделив изображение на сегменты, можно обрабатывать только важные сегменты изображения вместо обработки всего изображения.
Процесс сегментации изображения проходит в 3 этапа:
– сегментирование строк;
– сегментирование слов;
– сегментирование символов.
Под сегментацией строк подразумевается разделение изображения на текстовые строки, т. е. изображение делится на столько изображений поменьше, сколько на нем текстовых строк.
Сегментация слов, как и сегментация символов, происходит таким же образом, только для слов и символов соответственно.
Существуют несколько алгоритмов сегментации: сегментация за счет выявления средней яркости изображения, кластеризация K-средних и т. д.
Третий этап – распознавание символов. Когда человек читает текст, он распознает символы с помощью глаз и мозга. У компьютера в роли глаз выступает камера сканера, которая создает графическое изображение текстовой страницы. Для компьютера нет разницы между фотографией текста и фотографией комнаты: и то, и другое – набор пикселей.
Можно представить, что в русском алфавите есть только одна буква. Но даже это не упростит компьютеру процесс распознавания, т. к. у каждой буквы и любой другой графемы есть аллографы – различные варианты начертаний.
Человеку будет просто понять, что все эти аллографы подразумевают одну и ту же букву. Компьютер же имеет два варианта решения проблемы: распознавать символы целостно (распознавание паттерна) или использовать различные правила, которые описывают характер той или иной буквы (выявление признаков, или же функция извлечения).
Основными методами распознавания символов являются выявление признаков, распознавание паттернов и самое распространенное решение – использование нейронной сети.
Шаг 1. Обработка изображения. Пусть Imagei и Imagei+1 два входных изображения, текст в которых необходимо распознать. Из-за разности в качестве (свойства, характеристики) входных изображений может случиться так, что для обработки изображения одно сочетание алгоритмов будет менее эффективным, чем другое. Представим, что A – множество возможных сочетаний алгоритмов обработки изображения. Необходимо составить такие сочетания, являющиеся множествами Bi, которые включали бы в себя алгоритмы каждого из этапов обработки изображения
Вернемся ко входным изображениям Imageiи Imagei+1. Представим, что на первом изображении присутствует гауссовский шум, а на втором равномерно расположенный шум. При наличии
в подмножестве Bi алгоритма размытия по Гауссу, а в подмножестве Bi+1 алгоритма медианной фильтрации по анализу алгоритмов из первой части можно понять, что наиболее эффективно первое изображение обработает алгоритм из подмножества Bi, а второе изображение – Bi+1. Следовательно, при наличии одного из алгоритмов размытия (сглаживания), входное изображение с другим типом шума обработается хуже, что может привести к ошибкам работы алгоритмов в следующих этапах.
Чтобы избежать таких проблем, было предложено использовать множество сочетаний алгоритмов обработки изображения.
Шаг 1. Этап 1. Перевод изображения в оттенки серого. Для перевода изображения в оттенки серого необходимо написать алгоритм, который производит преобразования значений пикселей трех цветовых каналов (RGB) матрицы изображения:
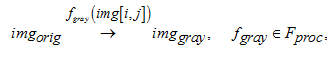
где imgorig – входная матрица пикселей изображения с размерами mxn (m – количество рядов, n – количество пикселей в ряду); img[i, j] – кортеж из 3 элементов, значений цветовых каналов, каждый из которых принимает значения из диапазона [0, 255]; imggray – выходная матрица пикселей изображения в оттенках серого с размерами mxn; fgray(img[i, j]) – алгоритм перевода изображения
в серый.
Шаг 1. Этап 2. Формирование множества алгоритмов размытия изображения. На этом этапе формируется множество алгоритмов размытия (сглаживания) изображения. Входное изображение в оттенках серого подается на вход множеству алгоритмов размытия, и на выходе получается множество размытых разными алгоритмами изображений:
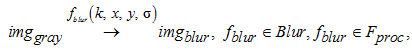
где fblur(k, x, y, σ) – алгоритм размытия изображения, k – ядро свертки, x – горизонтальное смещение от центра ядра свертки, y – вертикальное смещение от центра ядра свертки, σ – среднеквадратичное отклонение нормального распределения (только для Гаусса); imgblur – матрица пикселей размытого изображения; Blur – множество алгорит-
мов размытия.
Шаг 1. Этап 3. Формирование сочетаний алгоритмов размытия с алгоритмами бинаризации. На этом этапе формируется множество алгоритмов бинаризации изображения и их связки
с множеством алгоритмов размытия:
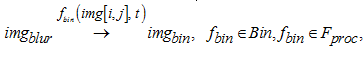
где fbin(img[i, j], t) – алгоритм бинаризации изображения (пороговая фильтрация), t – глобальный/локальный порог, по которому будут преобразовываться значения пикселей изображения;
imgbin – матрица пикселей бинарного изображения; Bin – множество алгоритмов бинаризации.
Для формирования множества сочетаний алгоритмов обработки рассмотрим множество алгоритмов размытия и множество алгоритмов бинаризации [7]:

Для формирования множества сочетаний (BB) необходимо применить декартово произведение множеств:
![]() (2)
(2)
Используя формулу (2), получаем множество BB:
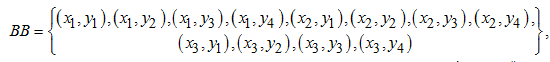
где x1–x3 – алгоритмы размытия; y1–y4 – алгоритмы бинаризации.
Шаг 1. Этап 4. Выравнивание изображения. Этап выравнивания изображения может быть опциональным. В организации в основном поступают неоцифрованные документы, которые не имеют проблем в выравнивании. Однако во избежание возможных проблем необходимо иметь представление о процессе выравнивания изображения:
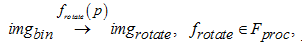
где p – координаты (x, y) четырех точек самого большого контура (прямоугольника, трапеции, ромба и т. п.) на изображении; frotate(p) – алгоритм перспективного преобразования (выравнивание); imgrotate – выравненное изображение.
Шаг 1. Этап 5. Удаление лишних линий:
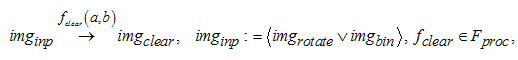
где imginp – матрица пикселей бинарного или выравненного изображения (в зависимости от выполненного ранее алгоритма); fclear(a, b) – алгоритм удаления лишних линий с использованием морфологической обработки, a – порог фильтрации, b – полутоновая маска; imgclear – матрица пикселей очищенного изображения от нежелательного контента.
Шаг 2. Сегментация изображения. Следую-
щим шагом после обработки изображения является сегментация изображения на символы:
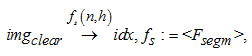
где imgclear – матрица пикселей обработанного изображения; fs(n, h) – алгоритм выявления среднего значения яркости изображения (сегментация), n – ширина изображения, h – высота изображения; idx – множество индексов границ изображения.
На основе множества границ изображения можно поделить основное изображение на более мелкие изображения символов. Пусть изображения символов обозначаются как imgsymb.
Шаг 3. Распознавание. Существует не одно решение для реализации шага распознавания, однако наиболее гибкое решение – использование нейронной сети. В формализованном виде преобразование изображений символов в текстовый набор выглядит следующим образом:
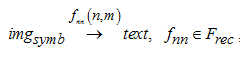 ,
,
где imgsymb – матрица пикселей входного изображения символа; text – распознанный текстовый набор; fnn(n, m) – алгоритм распознавания с использованием нейронной сети.
На вход подаются изображения символов, которые проходят каждый слой нейронной сети с распределением весов. Затем, исходя из обученности нейронной сети, формируется выходное значение, являющееся распознанным символом. На основе распознанных символов формируется слово и в дальнейшем сам текстовый набор.
В результате добавления правила формирования множества сочетаний алгоритмов обработки изображения модель процесса распознавания символов (1), где F: = <Fproc, Fsegm, Frec> – мно-
жество механизмов преобразования входного документа, Fproc – множество сочетаний алгоритмов обработки, преобразовывается (рис. 2).
В разработанной модели в множестве механизмов преобразования входного документа применяется множество сочетаний алгоритмов обработки изображения вместо одного сочетания.
.

Рис. 2. Формализация разработанной модели распознавания символов
на основе множества сочетаний алгоритмов обработки изображений
Fig. 2. Formalization of the developed character recognition model based
on a variety of combinations of image processing algorithms
Заключение
В ходе работы был предложен системный подход к распознаванию символов в зашумленных изображениях, разработан алгоритм формирования множества пар алгоритмов размытия и бинаризации.
Сформирована модель, позволяющая получить теоретико-множественные представления о последовательности алгоритмов обработки изображения и о возможном множестве сочетаний алгоритмов обработки изображений.
1. Natsional'nyi proekt «Maloe i srednee predprini-matel'stvo i podderzhka individual'noi predprinimatel'skoi initsiativy» [National project “Small and medium-sized entrepreneurship and support for individual entrepreneurial initiative”]. Available at: https://www.economy.gov.ru/material/directions/nacionalnyy_proekt_maloe_i_srednee_predprinimatelstvo_i_podderzhka_individualnoy_predprinimatelskoy_iniciativy/ (accessed: 10.06.2024).
2. Khomenko T. V., Tarakanov V. D., Irgaliev A. A. Avtomatizatsiya protsessa kontrolya oznakomleniya s dokumentami v organizatsiyakh s ierarkhicheskoi strukturoi [Automated control over inspecting documents in hierarchical organizations]. Vestnik Astrakhanskogo gosudarstvennogo tekhnicheskogo universiteta. Seriia: Upravlenie, vychislitel'naia tekhnika i informatika, 2023, no. 2, pp. 91-97.
3. Shchepilov E. V., Valenbakhova E. V., Goncharova N. P. Osobennosti obrabotki izobrazheniia v informatsionnykh sistemakh [Features of image processing in information systems]. Nauka i sovremennost', 2011. Available at: https://cyberleninka.ru/article/n/osobennosti-obrabotki-izobrazheniy-v-informatsionnyh-sistemah (accessed: 10.06.2024).
4. Maslov I. A. Opticheskoe raspoznavanie simvolov v informatsionnykh sistemakh i problemy vnedreniia [Opti-cal character recognition in information systems and prob-lems of implementation]. E-Scio, 2023. Available at: https://cyberleninka.ru/article/n/opticheskoe-raspoznavanie-simvo-lov-v-informatsionnyh-sis-temah-i-problemy-vnedreniya (accessed: 10.06.2024).
5. Efimov A. A., Kudrina M. A., Gordeeva O. A. Issle-dovanie vliianiia razlichnykh metodov predvaritel'noi obrabotki izobrazhenii na kachestvo raspoznavaniia teksta [Investigation of the influence of various image prepro-cessing methods on the quality of text recognition]. Nadezhnost' i kachestvo: trudy Mezhdunarodnogo simpoziuma. Penza, Penz. gos. un-t, 2020. N. 1. Pp. 285-288.
6. Shcheglov D. S., Goriachkin B. S., P'ianzin S. A. Optimizirovannyi podbor fil'trov pri opticheskom raspoznavanii simvol'noi informatsii [Optimized filter selection for optical character information recognition]. StudNet, 2020, no. 4, pp. 258-264.
7. Khomenko T. V., Irgaliev A. A., Tarakanov V. D. Modelirovanie protsessa opticheskogo raspoznavaniia v normativnykh dokumentakh organizatsii [Modeling of the optical recognition process in the regulatory documents of the organization]. Vestnik Astrakhanskogo gosudarstvennogo tekhnicheskogo universiteta. Seriia: Upravlenie, vychislitel'naia tekhnika i informatika, 2023, no. 3, pp. 85-92.
8. Doronin Iu. D. Metody obrabotki izobrazhenii i is-pol'zovanie komp'iuternogo zreniia v OCR [Image processing techniques and the use of computer vision in OCR]. Vestnik Moskovskogo gosudarstvennogo tekhnicheskogo universiteta, 2021, no. 5, pp. 4-5.
9. Stetsiuk V. B. Metody ustraneniia shumov na izobrazheniiakh [Methods for eliminating noise in images]. Aktual'nye problemy aviatsii i kosmonavtiki, 2019, vol. 2, pp. 176-178.
10. Gonsales R., Vuds R. Tsifrovaia obrabotka izobra-zhenii [Digital image processing]. Moscow, Tekhnosfera Publ., 2019. 1104 p.
11. Nikitenkov V. L., Poberii A. A. Binarizatsiia i seg-mentatsiia otskanirovannogo teksta [Binarization and seg-mentation of scanned text]. Vestnik Syktyvkarskogo universiteta. Seriia 1, 2013, no. 17, pp. 1-2.
