










Russian Federation
Russian Federation
Russian Federation
Russian Federation
Russian Federation
The problem of configuration of Kubernetes clusters is considered. Since cluster settings are made using YAML configuration files containing a large number of parameters, links to repositories (open and closed) and external data sources, it is quite easy to make a mistake that will incur significant costs in the future. When all the necessary data for the file is correctly prepared, it is necessary to arrange them correctly in accordance with the syntax of the YAML markup. The purpose of the work is to search for the optimal method of automati-zation of building a Kubernetes configuration file based on statistical data.The analysis of the Kubernetes configuration problem based on YAML files and the problem of interpreting statistical data into a structured YAML file is carried out and specific methods and approaches to solving these problems are proposed. The modified algorithm of multiple linear regression for working with the collected statistical data, the result of the output data of the algorithm and the flowchart of the pattern adapted for building YAML files are presented. The proposed approaches make it possible to use additional tools to work with Kubernetes test and production clusters, which reduces the complexity of developers' interaction with them and increases deployment speed and scalability. In addition, the described methods make it possible to simplify the administration of large networks and automate the process of creating configuration YAML files for popular software templates.
algorithm, file, configuration, class library, pattern
Введение
Конфигурация кластера Kubernetes состоит из нескольких компонентов, каждый из которых имеет свои особенности настройки. Основные принципы конфигурации кластера Kubernetes [1]:
1. Иерархическая структура ресурсов: Kubernetes использует иерархическую структуру ресурсов, начиная от кластера и заканчивая отдельными контейнерами. Каждый уровень конфигурации определяет свой контекст и содержит определения других ресурсов.
2. Атомарность данных: значения в конфигурации должны быть атомарными, т. е. не должны содержать вложенные структуры данных.
3. Инверсия контекста: с помощью символа $ можно ссылаться на другие ресурсы в конфигурации, что позволяет избегать дублирования кода.
4. Валидация конфигурации: перед применением конфигурация проверяется на наличие ошибок, чтобы избежать проблем в работе кластера.
Эти принципы применимы ко всем уровням конфигурации Kubernetes, начиная от определения Pod и заканчивая настройками кластера.
YAML (YAML Ain’t Markup Language) – это язык сериализации данных, который используется для описания структуры объектов и ресурсов в Kubernetes. YAML-файлы имеют определенную структуру и содержат информацию о ресурсах: их название, описание, конфигурацию и зависимости между ними [2].
При построении YAML-файла Kubernetes возможны следующие проблемы [3]:
– неправильная структура файла: YAML-файлы должны иметь определенную структуру, состоящую из уровней вложенности. Если структура файла нарушена, Kubernetes не сможет его обработать;
– ошибки в синтаксисе: YAML – это язык разметки, который требует строгого соблюдения синтаксиса. Ошибки в синтаксисе могут привести к тому, что Kubernetes не сможет прочитать файл конфигурации;
– дублирование ключей: в YAML-файлах не допускается дублирование ключей, т. к. это может привести к ошибкам в работе приложения;
– использование не валидных значений: некоторые свойства ресурсов в Kubernetes могут принимать только определенные значения. Если используется недопустимое значение, это может вызвать ошибки в работе приложения.
При изучении указанных проблем были рассмотрены проблемы конфигурации кластера и определены методы их решения с целью упрощения конфигурации кластера.
Проблема конфигурации кластера
Kubernetes состоит из двух основных объектов: Pod и Service [4]. Pod – это минимальный строительный блок в Kubernetes. Он представляет собой группу контейнеров, которые работают вместе и обеспечивают определенную функцию или сервис. Pod может содержать один или несколько контейнеров, каждый из которых выполняет свою часть приложения.
Service – это объект, который обеспечивает внешний доступ к Pod. Он создает виртуальный IP-адрес, который можно использовать для обращения к Pod внутри кластера. Service также может обеспечить балансировку нагрузки, автоматическое масштабирование и отказоустойчивость.
Существует несколько видов сервисов. Перечисленные ниже типы для простоты понимания можно рассматривать как «матрешку»: каждый последующий оборачивает предыдущий и добавляет некоторые правила маршрутизации. При создании сервиса более высокого уровня автоматически создаются сервисы нижележащего типа. Рассмотрим следующие типы сервисов [5]:
– ClusterIP – тип сервиса, существующий в любом кластере. Единая точка доступа к Pod-элементам по постоянному IP-адресу, доступному только изнутри кластера;
– NodePort – общий IP-адрес Pod-элементов (полученный из ClusterIP) соединяется с определенным портом всех Node-элементов, на которых развернуты обслуживаемые Pod-элементы. При этом Pod-элементы становятся доступны по адресу <NodeIP>:<NodePort>;
– LoadBalancer – выходной порт NodePort, который присоединяется к внешнему балансировщику нагрузки, предоставляемому облачным провайдером. Таким образом мы получаем статический внешний IP-адрес для нашего приложения.
При этом для конфигурации используются следующие объекты [6]:
– Namespace – пространство имен. Объекты могут взаимодействовать, только если находятся в одном пространстве имен. С помощью пространств имен возможно развернуть несколько виртуальных кластеров на одном физическом;
– ReplicaSet – контроллер, позволяющий создать набор одинаковых Pod-элементов и работать с ними как с единой сущностью. Он поддерживает нужное количество реплик, при необходимости создавая новые Pod-элементы или удаляя старые;
– Deployment – контроллер развертывания, являющийся абстракцией более высокого уровня над ReplicaSet'ом. Добавляет возможность обновления управляемых Pod-элементов;
– ConfigMap – объект с произвольными конфигурациями, которые могут, например, быть переданы в контейнеры через переменные среды;
– Secret – объект с некоей конфиденциальной информацией. Секреты могут быть файлами (SSL-сертификатами), которые монтируются к контейнеру, либо base64-закодированными строками, передающимися через те же переменные среды.
Для внесения небольших изменений в объекты действующего кластера можно использовать стандартную веб-консоль Kubernetes Dashboard, но для стартовой настройки всегда необходимо использовать файлы конфигурации формата YAML.
На построение синтаксически правильных файлов, как правило, уходит большое количество времени, кроме того, необходимо использовать корректные адреса репозиториев для загрузки образов контейнеров [7].
Алгоритм множественной линейной регрессии
Так как файл состоит из структурных стандартизованных блоков определенного типа, наполнение которых зависит от множества других параметров, для автоматизации процесса построения файла можно использовать алгоритм множественной линейной регрессии, применяемый при построении математических моделей для нейронных сетей. Воспользуемся уравнением множественной линейной регрессии, которое имеет следующий вид:
y = θ0 + θ1x1 + θ2x2 + … + θjxj + ε,
где y – зависимая переменная; θ0 – коэффициент, задающий базовый уровень; θ1, θ2, …, θj – коэффициенты изменения зависимой переменной; x1, x2, …, xj – независимые переменные; ε – коэффициент отклонения фактических данных от прогнозируемых.
В отличие от простой линейной регрессии в данном случае несколько признаков x (независимых переменных) и несколько коэффициентов θ.
Коэффициент θ0 задает некоторый базовый уровень при условии, что остальные коэффициенты равны нулю и зачастую не имеют смысла с точки зрения интерпретации модели.
Параметры θ1, θ2, …, θj показывают изменение зависимой переменной при условии «неподвижности» остальных коэффициентов.
Переменная ε (ошибка) представляет собой отклонение фактических данных от прогнозируемых. В этой переменной заложены две составляющие. Во-первых, она может включать вариативность целевой переменной, описанную другими (не включенными в указанную модель) признаками. Во-вторых, «улавливать» случайный шум, случайные колебания [8].
В предложенном алгоритме будет использована выборка данных на основе опыта пользователей. Кроме того, будут заданы известные стартовые эталонные данные для корректной работы алгоритма, представленные на рис. 1.
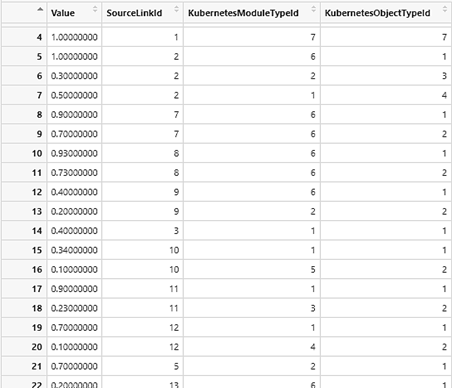
Рис. 1. Пример эталонных данных
для одного из шаблонов
Fig. 1. Example of reference data
for one of the templates
Математическая модель содержит в себе следующие переменные:
– идентификатор справочника типов объекта Kubernetes (Pod, Service и т. д.);
– идентификатор справочника ссылок на репозиторий Docker контейнера;
– идентификатор справочника типов модулей, используемых объектами Kubernetes, который представляет собой значение справочника модулей объектов Kubernetes, использующихся при создании кластера;
– зависимая переменная, вычисляемая для каждой записи в массиве данных.
На рис. 2 представлен пример файла Kubernetes с соответствием переменных предикторов с реальными сущностями файла.

Рис. 2. Пример файла конфигурации Kubernetes
Fig. 2. Example of Kubernetes configuration file
Перед применением алгоритма множественной линейной регрессии следует убедиться, что данные можно аппроксимировать с помощью линейной модели.
Для проверки линейной зависимости достаточно построить диаграмму рассеяния для каждой переменной-предиктора и переменной-ответа. Диаграмма рассеяния, построенная с помощью встроенных инструментов языка программирования R, представлена на рис. 3.

Рис. 3. Диаграмма рассеяния
Fig. 3. Scattering diagram
Как видно из диаграммы, каждая переменная-предиктор имеет линейную корреляцию с переменной отклика.
Далее можно проверить распределение невязок модели, которое должно быть нормальным. Для этого построим гистограмму остатков математической модели, представленной на рис. 4.
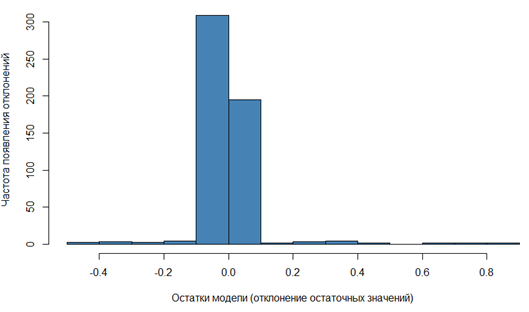
Рис. 4. Гистограмма остатков
Fig. 4. Histogram of residuals
Хотя распределение немного смещено вправо, оно не настолько ненормально, чтобы вызывать серьезные опасения.
Также нужно проверить выполнение условия гомоскедастичности. Чтобы проверить, соблюдается ли это предположение, построим график зависимости подходящего значения от остатка. График представлен на рис. 5.

Рис. 5. График зависимости подходящего значения от остатка
Fig. 5. Graph of the dependence of the appropriate value on the remainder
Как видно из графика, разброс имеет тенденцию к увеличению при малых подобранных значениях, но эта закономерность не вызывает большого беспокойства.
Для реализации алгоритма множественной линейной регрессии необходима стартовая матрица, состоящая из набора данных, описанного ранее. При этом набор данных запрашивается из заранее подготовленной базы данных по идентификатору справочника типа шаблона Kubernetes. Алгоритм состоит из следующих шагов [9]:
1. Исходная матрица транспонируется.
2. Транспонированная матрица перемножается с исходной.
3. Перемноженная матрица инвертируется.
4. Инвертированная матрица перемножается с транспонированной.
5. Из матрицы извлекается вектор коэффициента b для линейного уравнения y = b0 x0 + b1 x1 + b2x2 + … + bn xn, где bn – коэффициенты изменения зависимой переменной; xn – независимые переменные на основе выбранных предикторов и зависимой переменной.
6. На основании извлеченного вектора b вычисляется зависимая переменная y.
Полученные значения зависимой переменной обновляются в базе данных для всех отобранных записей и затем выбираются уникальные записи с самым большим коэффициентом для требуемого шаблона. Затем обработанные данные используем для построения конфигурационного файла Kubernetes.
В результате анализа массива данных с помощью алгоритма множественной линейной регрессии, собранных на основе опыта пользователей через web-приложение конструктора YAML-файлов, были составлены наборы объектов Kubernetes для разных шаблонов кластеров. Для каждого шаблона было взято около 500 оценочных значений в виде, представленном на рис. 6.

Рис. 6. Часть массива данных опыта пользователей
Fig. 6. Part of the user experience data set
Столбец Value содержит рассчитанное значение значимой переменной. Столбцы SourceLinkId, KubernetesModuleTypeId и KubernetesObjectTypeId содержат значения переменных-предикторов.
Были отобраны записи с наибольшими значимыми коэффициентами. Шаблоны и наборы объектов представлены в таблице.
Выходные данные алгоритма
The output of the algorithm
|
Шаблон |
Тип объекта |
Репозиторий Docker Hub |
Тип модуля объекта |
Значение зависимой переменной |
|
SPA |
Deployment |
Alpine https://hub.docker.com/_/alpine |
OS |
0,69 |
|
Service |
NGINX https://hub.docker.com/_/nginx |
Web server |
0,505 |
|
|
ASP NET Core WebApp SSR |
Deployment |
https://hub.docker.com/_/microsoft-dotnet-aspnet |
OS |
0,73 |
|
Service |
NGINX https://hub.docker.com/_/nginx |
Web server |
0,47 |
|
|
StatefulSet |
Postgres https://hub.docker.com/_/postgres |
DB |
0,39 |
|
|
Secret |
– |
API keys |
0,87 |
|
|
Service |
NextJS https://hub.docker.com/r/richardkovacs/nextjs |
SSR Web server |
0,45 |
|
|
DB Cluster |
StatefulSet |
Postgres https://hub.docker.com/_/postgres |
Master DB |
0,92 |
|
Slave DB |
0,64 |
|||
|
0,33 |
Для каждого шаблона отобраны определенные наборы модулей, без которых полноценное функционирование невозможно. Для кластера баз данных (шаблон DB Cluster) необходимы хотя бы один мастер-экземпляр и несколько зависимых. Одностраничному приложению (шаблон SPA) достаточно легковесного Linux дистрибутива Alpine и веб-сервера NGINX для доступа извне. Самым требовательным является полноценное веб-приложение (шаблон ASP NET Core WebApp SSR). Для него была подобрана среда с предустановленным пакетом SDK ASP NET Core, веб-сервер NGINX, база данных Postgres, сервис хранения API-ключей и веб-сервер NextJS для технологии серверного рендеринга контента страницы (SSR) [10]. По оценкам опыта пользователей указанные наборы объектов используют открытый исходный код и являются минимальными и достаточными.
Реализация сервиса построения конфигурационного YAML-файла для Kubernetes
Чтобы интерпретировать полученные данные после обработки алгоритмом в конечный файл конфигурации YAML, можно воспользоваться паттерном «Компоновщик» [11].
Паттерн состоит из следующих компонентов:
– Component: определяет интерфейс для всех компонентов в древовидной структуре;
– Composite: представляет компонент, который может содержать другие компоненты и реализует механизм для их добавления и удаления;
– Leaf: представляет отдельный компонент, который не может содержать другие компоненты;
– Client: клиент, который использует компоненты.
В упрощенной схеме паттерна реализацию компонента Leaf можно опустить при условии, что использоваться будут только составные иерархические объекты [12].
Как было сказано ранее, YAML-файл представляет собой иерархическую структуру составных объектов, что полностью совпадает со спецификой и областью применения паттерна «Компоновщик».
После выполнения алгоритма множественной линейной регрессии и обновления весовых коэффициентов на основе зависимой переменной из базы данных выбираются уникальные записи с самым большим коэффициентом для требуемого шаблона и передаются в сервис построения конфигурационных файлов Kubernetes. Данный сервис, применяя паттерн «Компоновщик» на основе входных записей требуемых объектов для данного шаблона, собирает конечный YAML-файл для дальнейшего его применения на Kubernetes кластере. Сервис реализован на языке C#. Схема работы реализованного сервиса представлена в виде диаграммы последовательности на рис. 7.

Рис. 7. Схема работы реализованного сервиса
Fig. 7. Scheme of operation of the implemented service
В диаграмме отражен основной бизнес-процесс сервиса построения конфигурационного YAML-файла для Kubernetes:
1. Пользователь отправляет http-запрос к сервису на формирование конфигурационного сервиса по требуемому шаблону.
2. Сервис запрашивает данные из реляционной СУБД, содержащей статистические и структурные данные.
3. Найденные данные возвращаются сервису.
4. Полученные данные обрабатываются с помощью алгоритма множественной линейной регрессии.
5. Рассчитанные коэффициенты записываются в СУБД.
6. СУБД возвращает наибольшие коэффициенты для обрабатываемого типа шаблона.
7. Применяется паттерн «Стратегия» для вызова класса в соответствии с типом шаблона.
8. Применяется паттерн «Компоновщик» для рекурсивного построения конфигурационного файла на основе коэффициентов, полученных в шаге 6.
9. Скомпонованный файл возвращается пользователю.
Заключение
Таким образом, используя алгоритм множественной линейной регрессии, можно добиться автоматизации процесса построения кластеров Kubernetes. Описанный метод позволит снизить временные и человеческие ресурсы, но при этом возрастут требования к производительности сервера, где будут происходить алгоритмические вычисления. При этом важно отметить, что затраты на вычислительные мощности всегда ниже остальных. К тому же, с постоянно обновляющимся массивом данных, основанным на опыте пользователей, сервис обеспечит возможность проводить аналитику удачных решений и применять их в будущем.
Описанный метод оптимизации может быть применен в различных сферах деятельности, где используются механизмы Kubernetes, без привязки к специфике и области работы, будь то образовательное учреждение либо коммерческое или государственное предприятие, т. е. метод является универсальным и эффективным средством построения кластеров Kubernetes.
Приведенный метод для построения конфигурационных YAML-файлов для Kubernetes позволяет автоматизировать процесс построения YAML-файла Kubernetes, который сводится к подготовке статистических обработанных данных и дальнейшей их интерпретации. Описанный метод построения файлов позволит снизить временные и человеческие ресурсы, кроме этого, возможность ошибки при построении кластера существенно снизится.
Сервис компоновщика файлов может быть использован и для построения других форматов файлов, имеющих как иерархическую, так и flat (плоскую) структуру.
1. Osnovy Kubernetes. Available at: https://habr.com/ru/articles/258443/ (accessed: 23.10.2023).
2. Objects In Kubernetes. Kubernetes. Available at: https://kubernetes.io/docs/concepts/overview/working-with-objects/ (accessed: 23.10.2023).
3. Managing YAML Errors for Kubernetes Configuration. Available at: https://dev.to/olabayobalogun/managing-yaml-errors-for-kubernetes-configuration-k85 (accessed: 23.10.2023).
4. Balzamov A. V., Fomin D. S., Savkina A. V., Nikulin V. V., Fedosin S. A. Development of a methodology for migration of monolithic systems to micro-service architecture using cloud technologies. Journal of Physics: Conference Series. 2021. 5. Seriia: 5th International Scientific Conference on Information, Control, and Communication Technologies, ICCT 2021. P. 012036.
5. Fomin D. S., Savkina A. V. Problemy realizatsii monolitnykh sistem [Problems of implementation of monolithic systems]. XLIX Ogarevskie chteniia: materialy Nauchnoi konferentsii: v 3 ch. Saransk, Natsion. issled. Mordov. gos. un-t im. N. P. Ogareva, 2021. Pp. 257-263.
6. Namespaces. Kubernetes. Available at: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/ (accessed: 24.10.2023).
7. Markelov A. Vvedenie v tekhnologii konteinerov i Kubernetes [Introduction to Container and Kubernetes Technologies]. Moscow, DMK Press, 2019. Pp. 110-152.
8. Mnozhestvennaia lineinaia regressiia [Multiple linear regression]. Available at: https://www.dmitrymakarov.ru/opt/mlr-04/#9-3-gomoskedastichnost-ostatkov (accessed: 25.10.2023).
9. Model' mnozhestvennoi lineinoi regressii: soder-zhatel'naia interpretatsiia i predposylki [Multiple linear regression model: meaningful interpretation and back-ground]. Available at: https://sun.tsu.ru/mminfo/2016/Dombrovski/book/chapter-3/chapter-3-1.htm (accessed: 25.10.2023).
10. Deitrei S., Kharrell F. Lineinaia regressiia s pri-merami prilozhenii [Linear regression with application examples]. Moscow, Vil'iams Publ., 2018. 800 p.
11. Gamma E., Khelm R., Dzhonson R. Patterny ob"ektno-orientirovannogo proektirovaniia [Object-oriented design patterns]. Saint Petersburg, Piter Publ., 2021. 142 p.
12. Frimen E., Robson E., S'erra K. Patterny proektiro-vaniia [Design patterns]. Saint Petersburg, Piter Publ., 2021. 640 p.
