











Astrakhan, Russian Federation
Astrakhan, Russian Federation
Astrakhan, Russian Federation
Improving the quality of classification of different documents is a purpose of modeling the optical character recognition. Non-digital documents, such as scanned or photographed documents, are difficult to classify correctly in electronic document management systems. A decision was made to simulate the process of optical character recognition in the regulatory documents of the organization. There have been considered various methods of modeling the process. The structure of departments for the electronic document management system is given. Methods of implementing optical character recognition (OCR) are considered. The stages of the OCR system development are revealed: image processing, segmentation, recognition. The methods of image processing are analyzed. The main processes associated with image processing are disclosed: alignment, blurring, binarization, finding contours, removing extra lines. Comparison of image blur methods is made. Two stages of image binarization are defined: conversion of a color image into a gray image, binarization of a gray image. The Kenny operator is proposed as a second stage of binarization, which is used to detect the boundaries of the image. The last stage of image processing is the process of removing extra lines. Algorithms for dividing text areas into segments are considered. 3 stages of segmentation are identified: string segmentation, word segmentation, character segmentation. A segmentation algorithm is defined based on calculating the average brightness of image pixels to search for different intervals: line spacing, word spacing, character spacing. Available popular online OCR services as well as some popular desktop programs are considered. A connection has been found between an artificial neural network and optical object recognition. To implement the recognition stage, it is proposed to use an artificial neural network.
image processing, segmentation, character recognition, binarization, blurring, image contours, artificial neural network, document classification, document flow, document familiarization, organization, management
Введение
В настоящее время большие организации все чаще имеют сложную иерархическую структуру [1]. При отсутствии системы электронного документооборота на предприятии отсутствует возможность эффективного и грамотного кадрового, налогового, управленческого и бухгалтерского учета [2]. При выдаче нового документа на ознакомление сотрудникам затрачивается много времени, а учет ознакомленных вести самостоятельно в материальном или электронном журнале неэффективно. Ознакомление сотрудника с документом, отправленным ему на электронную почту, отследить в полной мере практически невозможно, остается только полагаться на ответственность самих сотрудников [3]. Помимо всего прочего, на текущий момент наблюдается дефицит бумаги, что приводит к еще большим временным и материальным расходам для организации [4]. Современные предприятия отходят от ручной волокиты и доверяют некоторые задачи компьютеру, и оборот документов не стал исключением. Благодаря системам электронного документооборота (СЭД) [5] сокращается время, затрачиваемое сотрудниками на данную работу, а также снижается нагрузка на персонал [3]. Одна из задач СЭД – выдача нормативного документа на ознакомление сотруднику определенного подразделения. На этот процесс уходит немалое количество времени. Но благодаря современным тенденциям можно повысить эффективность решения поставленной задачи. Система электронного документооборота может использовать методы искусственного интеллекта [6], которые позволяют определять класс документа, исходя из ключевых слов, и подбирают возможные варианты подразделений и сотрудников, чьи компетенции удовлетворяют классу документа. Такой процесс называют классификацией документов [7]. Классификация документов происходит путем ознакомления программного обеспечения с документами, т. е. система определяет, сопоставляется ли содержимое документа с компетенциями какого-либо подразделения, для этого она должна изучить этот документ. Компьютер, в отличие от человека, не может отличить изображение от оцифрованного документа, поэтому при классификации документов может возникнуть проблема низкого качества классификации в связи с нецифровым форматом нормативных документов. Решить данную проблему помогает процесс оптического распознавания символов (ОРС) в нормативных документах. Благодаря данному процессу СЭД сможет эффективнее определять ключевые слова того или иного нормативного документа и классифицировать его для дальнейшего выявления потенциальных подразделений-получателей. Подобные программы с открытым исходным кодом уже разрабатывались, например в [8], но проблема в том, что данная программа разработана для операционной системы Linux, что сужает круг ее использования. Остальные системы либо не open source, либо имеют слишком высокую стоимость, либо имеют много лишних функций и их нельзя прикрепить модулем к СЭД. В связи с этим актуальной научной задачей является моделирование процесса ОРС для системы электронного документооборота.
Документооборот в организации
В больших организациях сотрудники делятся на группы (подразделения), каждая из которых выполняет определенную задачу.
Для системы электронного документооборота была выбрана следующая иерархическая структура подразделений:
– каждое подразделение имеет одного руководителя и постоянного заместителя руководителя (может не иметь постоянного заместителя);
– каждое подразделение имеет одного или
несколько временных заместителей руководителя (может не иметь временных заместителей);
– каждое подразделение имеет родителя (подразделение, которое стоит выше по иерархии).
Подразделение, не имеющее родителя, стоит на одном из самых высоких мест по иерархии.
Как описано выше, существуют подразделения, функционирование которых связано с определенным родом деятельности в организации. В каждом подразделении сотрудник назначается на определенную должность. Выбрана модель, в которой к группам привязывается не сотрудник, а определенная должность, на которую впоследствии назначается сотрудник.
После выбора модели подразделений (групп) решается задача ознакомления сотрудников организации с нормативными документами.
Сами нормативные документы в систему загружает Директор системы.
Так как в каждом подразделении обязательно есть руководитель, то при поступлении в систему какого-либо нормативного документа первым данный документ от Директора получает руководитель подразделения (в соответствии с компетенциями документа), после чего пересылает полученный документ своим подчиненным и, если нужно, пересылает руководителю нижестоящей по иерархии группы.
Оптическое распознавание символов
При добавлении нового нормативного документа в СЭД может оказаться так, что загружаемый документ имеет нецифровой вид, т. е. он может быть изображением. В дальнейшем в СЭД будет добавлен модуль классификации документов, поэтому все загружаемые документы должны быть в текстовом виде. Этого поможет достигнуть модуль ОРС.
Данный модуль включает три этапа: обработка изображения, сегментация и само распознавание объектов [9] (рис. 1).
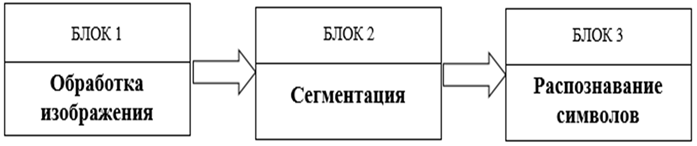
Рис. 1. Схема этапов процесса распознавания символов
Fig. 1. Diagram of the stages of the character recognition process
Обработка изображения
Первый этап в распознавании символов – обработка изображения (см. рис. 1, блок 1). Обработка изображений – форма обработки информации, входным параметром которой является изображение, например фотография или отсканированный документ. Обработка изображений может осуществляться как для получения изображения на выходе (например, подготовка к полиграфическому тиражированию, к телетрансляции и т. д.), так
и для получения другой информации (распознавание текста).
Поскольку документы редко бывают отсканированы ровно, текст документа может оказаться в какой-то степени наклонен, что ухудшает качество распознавания. Поэтому необходимо произвести процесс выравнивания изображения. Этого можно добиться за счет выявления строк текста
и приведения их к горизонтальным (рис. 2).
Для сглаживания изображения (удаления шума) можно использовать два распространенных метода: размытие по Гауссу и медианное размытие.

Рис. 2. Выравнивание за счет выявления горизонтальных линий
Fig. 2. Alignment by detecting horizontal lines
Медианное размытие более эффективно против шума от «соли». Но чаще всего в изображении для распознавания присутствует «гауссовский шум»,
а не шум от «соли», поэтому эффективнее использовать размытие по Гауссу (рис. 3).


Рис. 3. Переход от исходного изображения к размытому
Fig. 3. Transition from the original image to a blurry image
Как известно, размытие по Гауссу производится через функцию Гаусса. Функция Гаусса используется для вычисления преобразования, применяемого к каждому пикселю изображения. Формула функции Гаусса в одном измерении [10]:
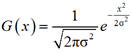
где G – функция Гаусса; x – горизонтальная координата точек; σ – среднеквадратическое отклонение нормального распределения; e – число Эйлера, неперово число.
В двух измерениях это произведение двух функций Гаусса, по одной для каждого измерения:
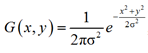
где y – вертикальная координата точек.
Цветное изображение можно представить, как двумерные массивы со слоями (каналами), представляющими цвет. Любой элемент такого массива в каждом слое сохраняет интенсивность этого пикселя в канале, поэтому при сложении пикселей из каждого канала создается уникальный общий цвет пикселя изображения [11].
После выравнивания изображения необходимо провести бинаризацию, т. е. перевести входное цветное изображение в черно-белое (бинарное). Сразу перевести цветное изображение в черно-белое достаточно сложно, поэтому данный процесс можно разделить в два этапа: представление цветного изображения в градациях серого, перевод серого изображения в бинарное [12].
Представление цветного изображения в градациях серого не представляет трудности, т. к. значение серого цвета каждого пикселя можно вычислить через три составляющих каждого цветного пикселя: цветовая схема RGB:
![]()
где R – красный слой; G – зеленый слой; B – синий слой.
Второй этап, а именно перевод серого изображения в бинарное, состоит из перевода каждого серого пикселя, значение которого от 0 до 255,
в бинарное значение – 0 и 1, где 0 – белый цвет (передний план), 1 – черный цвет (фон).
Для этого можно использовать оператор Кен-
ни [13], который позволяет находить границы изображения (рис. 4).

Рис. 4. Поиск границ изображения через оператор Кенни
Fig. 4. Finding for image boundaries by using the Kenny operator
В качестве дополнительного этапа перед использованием оператора Кенни можно провести процесс уменьшения количества пикселей изображения. Это в какой-то степени поможет более точно найти необходимые границы с помощью оператора Кенни, а также ускорит работу во столько раз, во сколько сожмется изображение.
После того как найдены границы текста, можно преобразовать изображение в удобный для дальнейших манипуляций вид: белый фон, черные символы – это необходимо для дальнейшей сегментации, после чего необходимо удалить все лишние линии, которые не являются текстом. Используемые для этого алгоритм Блумберга и морфологическая обработка представлены в [12].
Сегментация
Вторым этапом в распознавании символов является сегментация (см. рис. 1, блок 2). Когда изображение обработано, необходимо поделить его на сегменты: строки, слова и буквы. Это необходимо для того, чтобы распознавать каждый символ по отдельности, затем распознанные символы соединять в слова и проверять их на корректность. Допустим, нужно распознать слово «ноль». Так как по характеристикам буква «о» схожа с цифрой «0», система может распознать эту букву неверно. Для сокращения количества ошибок слова, после соединения букв, проверяются на корректность. Проверка выдаст, что слова «н0ль» не существует, но есть слово «ноль», и скорректирует его.
Будем рассматривать не цветное изображение, т. к. в этом случае проще разделять изображение на текстовые области. Для этого будем использовать матрицу яркости C = {cij}, где i принимает значения от 1 до n, а j принимает значения от 1 до m (n – ширина изображения, а m – высота) [14].
Для определенности будем считать, что cmax – это максимальная яркость пикселя, т. е. черный цвет, а cmin – это минимальная яркость (равная 0),
т. е. белый цвет: ![]()
Сегментация происходит в 3 этапа: сегментация строк, сегментация слов, сегментация символов.
1. Задача разделения изображения на строки решается нахождением верхних и нижних границ текстовой области. Так как пиксели изображения делятся на более яркие и менее яркие, после обработки изображения фон становится менее ярким (светлее), а текстовая область – более яркой (темнее).
Для начала найдем средние значения яркости для всех пиксельных строк:
![]()
Затем определим среднее значение яркости всего изображения:
![]()
Средняя яркость межстрочных интервалов минимальна (равна 0). Исходя из этого яркость верхней границы, как и яркость нижней границы, можно определить через среднюю яркость всего изображения: ![]() соответственно, где 0 ≤ k ≤ 1.
соответственно, где 0 ≤ k ≤ 1.
Работа алгоритма заключается в последовательной проверке массива средних значений яркости строк (row1, …, rowm) и выявлении множеств пар индексов rowtopi и rowbotti, являющихся верхней и нижней границами строки i.
2. В качестве входных данных второго этапа сегментации выступают изображения, отражающие только строки, найденные на первом этапе.
Для более точного разделения строки на слова входное изображение необходимо дополнительно обработать: увеличить контрастность изображения (удалить шум и лишние точки) и применить «размазывающий» фильтр.
Алгоритм основывается на том, что средняя яркость межсловных интервалов гораздо ниже средней яркости областей со словами. Он схож с алгоритмом сегментации строк, но просмотр средней яркости производится не по строкам, а в столбец.
Для начала найдем среднее значение яркости для всех пиксельных столбцов:
![]() (1)
(1)
Затем определяем среднее значение яркости изображения строки:
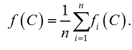
Яркость левой границы (начало слова), как
и яркость правой границы (конец слова), можно выразить через среднюю яркость изображения строки: ![]() соответственно, где 0 ≤ k ≤ 1.
соответственно, где 0 ≤ k ≤ 1.
Работа алгоритма сегментации слов заключается в последовательной проверке массива средних значений яркости столбцов (col1, …, coln) и выявлении множеств пар индексов collefti и colrighti пиксельных строк, являющихся левой и правой границами слова i.
3. Процесс сегментации символов самый сложный, т. к. межсимвольные интервалы в большинстве изображений не так явно выделены, как межстрочные или межсловные.
Общая схема алгоритма сегментации символов состоит из двух этапов: поиска локальных минимумов и удаления ложных границ.
Поиск локальных минимумов производится на соседних интервалах изменения индекса столбца. Размер интервала определяется на основе высоты строки. Для большинства шрифтов соотношение ширины символа и его высоты не превышает 0,3. Исходя из этого размер интервала равен hj =0,3 м
Поиск минимума производится следующим
образом:
1. Найдем для всех пиксельных столбцов их среднее значение яркости. Необходимо использовать формулу (1).
2. Среди значений ci выполняется поиск первого минимума в диапазоне от 1 до hj.
3. При найденном минимуме с индексом i1min следующий минимум ищем в диапазоне от i1min + 1 до i1min + 1 + hj.
4. Процедура поиска повторяется, пока не будет достигнута граница изображения слова (i = n). Все значения ijmin, которые соответствуют локальным минимумам, сохраняются в списке W0.
Процесс удаления ложных границ проводится в несколько этапов.
Локальный минимум в столбце i является претендентом на принадлежность к межсимвольному интервалу, если значение средней яркости coli
в рассматриваемом столбце меньше выделенной границы яркости cb (b – bottom, нижняя граница яркости) и при этом значение средней яркости
в столбцах, удаленных от данного локального минимума на 2 пикселя с двух сторон, больше границы яркости.
Формула для вычисления границы яркости:
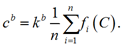
В конечном итоге из списка индексов локальных минимумов W0 исключаются индексы столбцов, средняя яркость которых не удовлетворяет данному условию. Формируется второй список (W1) с претендентами на принадлежность к межсимвольным интервалам.
На данном этапе в списке претендентов остались ненужные границы, которые делят символ на части. Это может происходить с широкими слабосвязанными символами, такими как Ц, П, Н и др. Необходимо поделить изображение символа на 3 уровня по вертикали и анализировать уровни отдельно. Разделение изображения происходит следующим образом: верхний уровень – 30 % от высоты символа, средний уровень – 45 % от высоты символа, нижний уровень – 60 % от высоты символа.
Для максимумов яркости каждого уровня highk, mediumk и lowk столбца k и максимумов яркости уровней highk + 1, mediumk + 1 и lowk + 1 столбца k + 1 требуется, чтобы выполнялось следующее условие:
![]()
Средняя яркость столбца k должна быть меньше максимума яркости соседнего столбца k + 1.
Максимум яркости в столбце k должен быть больше удвоенного абсолютного значения разности между значениями максимумов яркости столбца k и соседнего столбца k + 1.
Если для рассматриваемого столбца выполняются все требования связности с соседями с каждой из сторон, то граница удаляется как ошибочная, иначе производится повторная проверка. Расстояние до левой границы hk должно быть больше допустимого минимума hmin(![]() ).
).
Далее из списка индексов претендентов W1 исключаются индексы столбцов, которые имеют связь с соседними столбцами (ложные границы), и формируется конечный список индексов границ W2.
Распознавание символов
Для распознавания (см. рис. 1, блок 3) можно использовать функцию извлечения. После сегментации, когда система знает, какие символы нужно распознать, каждый символ сравнивается с различными правилами, которые описывают некий возможный характер символа. Например, две вертикальные линии равной высоты, соединенные одной горизонтальной линией приблизительно в середине, вероятно, являются буквой «н».
Достоинством данного метода является отсутствие ограничений на определенные шрифты или размеры, недостатком – сложность программирования различных правил, характеризующих символы.
Для распознавания объектов можно использовать полносвязную искусственную нейронную сеть (рис. 5) [15], которая состоит из 3 слоев: входного, скрытого и выходного.
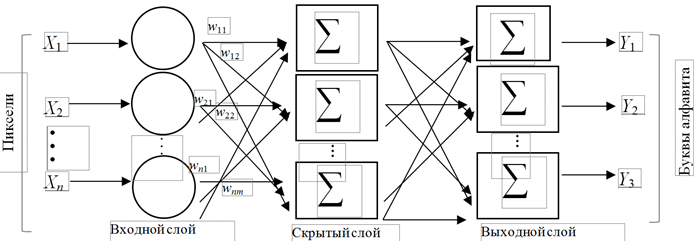
Рис. 5. Схема полносвязной нейронной сети: X – входные данные; Y – выходные данные
Fig. 5. Diagram of a fully connected neural network: X – input data; Y – output data
На вход нейросети подаются пиксели изображения, т. е. данный слой состоит из n × m нейронов, где n – высота изображения, а m – ширина. Выходной слой состоит из k нейронов, где k – размер используемого алфавита. Для каждого слоя, кроме первого, входным параметром будет являться выходной вектор предыдущего слоя.
Входными данными (X) являются пиксели изображения, например 28 × 28 пикселей – изображение распознаваемого символа. Выходными данными (Y) будут являться распознанные символы некоего алфавита, например 62 различных символа (A–Z, 0–9).
Индуцированное локальное поле u (иными словами, сумматор) и функция активации f(u) выглядят следующим образом:
![]()
где u – индуцированное локальное поле; f(u) – функция активации; wij – веса ходов; xi – сигналы на входах нейрона (пиксели изображения); w0x0 – инициализация нейрона.
Использование спроектированной модели процесса позволит ускорить процесс проведения ознакомления с документом в организации за счет сокращения времени подготовки документа к обработке.
Заключение
В ходе работы исследованы основные этапы обработки изображения. Выявлены необходимые методы, позволяющие наиболее корректно подготовить изображение для дальнейшей работы с ним: наиболее подходящий метод размытия изображения, основанный на задаче оптического распознавания символов; в качестве второго этапа бинаризации предложено использование оператора Кенни, необходимого для нахождения границ на изображении; для удаления лишних линий предложен метод Блумберга с морфологической обработкой.
Проанализированы методы для разделения изображения на нужные сегменты, выявлены необходимые этапы: алгоритм сегментации строк, основанный на средней яркости пикселей межстрочных интервалов; алгоритм сегментации слов, основанный на средней яркости пикселей межсловных интервалов; алгоритм сегментации символов, основанный на средней яркости пикселей межсимвольных интервалов.
Спроектирована возможная схема искусственной нейронной сети для этапа распознавания символов.
Спроектированная модель процесса распознавания символов может применяться для автоматизации документооборота в организациях.
1. Anufrieva O. B. Organizacionnaya struktura kak vazhnyy mehanizm upravleniya predpriyatiem // Vestn. Novosib. gos. un-ta. Ser.: Social'no-ekonomicheskie nauki. 2007. № 3. S. 5-6.
2. Levashina E. O. Analiz ispol'zovaniya sistem elektronnogo dokumentooborota organami ispolnitel'noy vlasti Rossiyskoy Federacii // Vestn. Astrahan. gos. tehn. un-ta. Ser.: Upravlenie, vychislitel'naya tehnika i informatika. 2013. № 2. S. 153-157.
3. Bobyleva M. P. Upravlencheskiy dokumentooborot: ot bumazhnogo k elektronnomu. Voprosy teorii i praktiki. M.: TERMIKA.RU, 2019. 470 s.
4. Elenceva L. Snizhenie rashodov na pechat' i bumagu. URL: https://kontur.ru/diadoc/spravka/21936-snizhenie_rasxodov_na_pechat_i_bumagu (data obrascheniya: 23.10.2022).
5. Zamyckih P. V. Avtomatizaciya prinyatiya upravlencheskih resheniy pri operativnom uchete hoda proizvodstva na osnove sistem elektronnogo dokumentooborota: avtoref. dis. … kand. tehn. nauk. M., 2013. 24 s.
6. Perova M. V., Sibileva A. A. Iskusstvennyy intellekt v sistemah elektronnogo dokumentooborota // Tendencii razvitiya nauki i obrazovaniya. 2022. № 81-2. S. 33-36.
7. Fedotov A. M., Prozorov O. V., Fedotova O. A., Bapanov A. A. O podhode k tematicheskoy klassifikacii dokumentov // Vestn. Novosib. gos. un-ta. Ser.: Informacionnye tehnologii. 2017. № 1. S. 1-2.
8. Programma dlya opticheskogo raspoznavaniya simvolov «OCRFeeder». 2009. URL: https://pingvinus.ru/program/ocrfeeder (data obrascheniya: 15.11.2022).
9. OCR algorithms: a complete guide. URL: https://www.itransition.com/blog/ocr-algorithm (data obrascheniya: 12.11.2022).
10. Stecyuk V. B. Metody ustraneniya shumov na izobrazheniyah // Aktual'nye problemy aviacii i kosmonavtiki: sb. materialov V Mezhdunar. nauch.-prakt. konf., posvyasch. Dnyu kosmonavtiki (Krasnoyarsk, 08-12 aprelya 2019 g.): v 3-h t. Krasnoyarsk: Izd-vo Sib. gos. un-ta nauki i tehnologiy im. akad. M. F. Reshetneva, 2019. T. 2. S. 176-178.
11. Doronin Yu. D. Metody obrabotki izobrazheniy i ispol'zovanie komp'yuternogo zreniya v OCR // STUDNET. 2021. T. 4. № 5. Poryadkovyy № 94.
12. Nikitenkov V. L., Poberiy A. A. Binarizaciya i segmentaciya otskanirovannogo teksta // Vestn. Syktyvkar. un-ta. Ser. 1. 2013. № 17. S. 113-123.
13. Kalinichenko Yu. V. Analiz algoritmov vydeleniya konturov cifrovyh izobrazheniy // Nauch. tr. SWORLD. 2015. № 1 (38). S. 14-17.
14. Segmentaciya izobrazheniya teksta. URL: https://mechanoid.kiev.ua/cv-text-image-segmentator.html (data obrascheniya: 10.11.2022).
15. Navoychik A. V., Gurin N. I. Raspoznavanie tekstovyh izobrazheniy pri pomoschi neyronnyh setey // Informacionnye tehnologii v obrazovanii, nauke i proizvodstve: IV Mezhdunar. nauch.-tehn. internet-konf. (Minsk, 18-19 noyabrya 2016 g.). Minsk: Izd-vo BNTU, 2016. URL: https://rep.bntu.by/bitstream/handle/data/27276/Raspoznavanie_tekstovyh_izobrazhenij.pdf?sequence=1&isAllowed=y (data obrascheniya: 20.10.2022).
