










Russian Federation
Russian Federation
The problem of choosing a database architecture for storing and processing heterogeneous and dynamically changing data is considered. Modern information systems generate large amounts of structured, semi-structured and unstructured data from multiple sources, which makes the task of choosing an architecture multi-criteria and associated with high uncertainty. An intelligent decision support model based on a hybrid approach combining the methods of fuzzy logic and neural network analysis is proposed. Fuzzy logic is used to formalize expert knowledge and work with linguistic parameters such as “high load” or “low circuit flexibility”. It allows you to process blurred boundaries of criteria and build an IF–THEN rule system for architecture selection. The neural network component provides training based on historical data, identification of nonlinear patterns and adaptation to new conditions. Their integration is implemented in the form of a neuro-fuzzy model (for example, ANFIS), which combines the explicitness of the rules with the possibility of further training. The proposed architecture includes three levels: normalization and fuzzification of input data, a block of logical output with defuzzification and a corrective neural network subsystem. At the output, a probabilistic assessment of the priorities of architectural solutions is formed - relational, document–oriented, graph, column, or hybrid. Examples of rules, modeling results, and practical application scenarios are given: IP design, migration between databases, support for DevOps processes, and educational tasks. The practical significance of the research lies in reducing dependence on subjective expert assessments and increasing the reproducibility of architectural solutions. The prospects of expanding the rule base, applying deep network architectures, and integrating the model into engineering tools are emphasized.
data processing, databases, fuzzy logic, neural networks
Введение
Развитие цифровых технологий сопровождается экспоненциальным ростом объемов и разнообразия данных, формируемых в различных предметных областях – от промышленности и медицины до социальных сетей, электронных сервисов и умных устройств. В современных информационных системах данные поступают из множества источников: реляционных таблиц, документов, сенсоров, API внешних сервисов, видео- и аудиопотоков. Такие данные различаются не только по структуре (структурированные, полуструктурированные, неструктурированные), но и по семантике, частоте обновления, объему, скорости поступления и степени достоверности.
Современные системы управления базами данных (СУБД) предъявляют высокие требования к адаптивности архитектуры, масштабируемости, устойчивости к сбоям и производительности. При этом выбор конкретной архитектуры базы данных становится задачей многокритериального характера: необходимо учитывать свойства данных, требования к хранению и извлечению, предполагаемую нагрузку, ограничения по аппаратным и программным ресурсам.
Классические подходы к выбору архитектуры СУБД опираются на опыт проектировщика и экспертные оценки, которые, как правило, содержат значительную долю неопределенности. Формализация таких процессов требует применения моделей, способных учитывать нечеткие или неточные значения, а также способных обучаться и адаптироваться на основе накопленного опыта. В этой связи становится актуальным применение методов нечеткой логики для учета экспертных суждений и нейросетевых моделей для обучения на исторических данных и выявления скрытых закономерностей. Использование гибридного подхода, сочетающего оба эти метода, позволяет разработать интеллектуальную модель поддержки принятия решений по выбору архитектуры баз данных, наиболее подходящей для хранения и обработки разнородных данных. Целью исследования является разработка обобщенной теоретической модели выбора архитектуры базы данных, обеспечивающей эффективное хранение и обработку разнородных данных, с использованием аппарата нечеткой логики и методов нейросетевого моделирования.
Для достижения поставленной цели решаются следующие научные задачи:
1. Разработать модель выбора архитектуры на основе нечеткой логики; модель должна учитывать экспертную неопределенность и многокритериальность.
2. Реализовать компоненты нейросетевого анализа, направленного на автоматическое распознавание характеристик входных данных и прогноз архитектурных решений.
3. Провести теоретическую оценку устойчивости, интерпретируемости и обобщающей способности предложенной модели. Описать потенциальные сценарии практического применения модели в рамках проектирования информационных систем.
Объектом исследования выступают архитектурные решения, применяемые в системах управления базами данных, ориентированных на работу с данными различной природы.
Предмет исследования составляет совокупность методов, подходов и инструментов, позволяющих формализованно и обоснованно выбирать архитектуру СУБД, адекватную заданному классу разнородных данных, на основе теоретических моделей нечеткой логики и нейросетевых вычислений.
Выбор архитектуры рассматривается как формализуемая интеллектуальная задача, решаемая при помощи гибридного подхода, объединяющего экспертную интерпретируемость (через нечеткие правила) и машинное обучение (через нейросети).
Применение нечеткой логики и нейросетей в задачах выбора архитектуры баз данных
Выбор архитектуры базы данных (БД) в современных условиях является нетривиальной задачей, поскольку сопровождается высокой степенью неопределенности и многокритериальностью. Неопределенность проявляется в том, что входные данные, такие как требования к системе, могут быть заданы неполно, меняться со временем или зависеть от внешних факторов. Кроме того, критерии оценки архитектуры могут быть разнородными – например, необходимо одновременно учитывать высокую скорость доступа, гибкость схемы, низкую стоимость, надежность и другие параметры. Эти критерии зачастую вступают в противоречие друг с другом: так, высокая производительность может конфликтовать с требованиями к надежности или гибкости системы. Дополнительную сложность создает нелинейный характер взаимосвязей между параметрами: например, увеличение объема данных не всегда приводит к линейному снижению производительности, особенно с учетом особенностей конкретной СУБД и ее архитектурных ограничений [1–3].
Традиционные методы принятия решений (например, табличный анализ или логические схемы) часто предполагают наличие четких значений параметров и жестких порогов (например, «если нагрузка > 1 000 запросов в секунду, используем NoSQL»), что не отражает реальной картины.
В связи с этим актуальным становится использование интеллектуальных методов, способных оперировать расплывчатыми (нечеткими) входами, учиться на опыте и учитывать многокритериальность оценки.
Основы нечеткой логики и ее применение в оценке критериев
Нечеткая логика (fuzzy logic), введенная Лотфи Заде в 1965 г., предоставляет формальный аппарат для описания неопределенных, лингвистических или частично определенных значений через функции принадлежности и нечеткие множества. В контексте выбора архитектуры СУБД ее применение позволяет описывать характеристики в естественной форме, например «высокая нагрузка», «низкая гибкость», «средняя надежность». Такой подход учитывает градуальные изменения без необходимости четких границ, что особенно важно при оценке показателей, близких по значению (например, 980 и 1 000 запросов в секунду – практически одинаковые показатели). Кроме того, нечеткая логика позволяет формировать правила на основе экспертных знаний, например, если нагрузка высокая и данные полуструктурированные, то предпочтительна документоориентированная СУБД. Модель нечеткой системы оценки архитектуры включает несколько компонентов. На вход поступают параметры, такие как степень масштабируемости, структура данных, интенсивность операций чтения и записи, требуемая гибкость схемы, необходимость транзакционной поддержки и др. Каждому параметру соответствуют функции принадлежности, определяющие лингвистические переменные вроде «низкий», «средний», «высокий». Далее используется база правил, содержащая логические конструкции вида IF–THEN, на основе которых осуществляется вывод с применением одного из механизмов – Mamdani или Sugeno, – позволяющего агрегировать и обобщать знания. Завершающий этап – дефаззификация, т. е. переход от нечеткого результата к конкретному решению, выражающемуся в выборе одного или нескольких типов архитектуры СУБД [3–5].
Пример: правило нечеткой системы
Если (нагрузка = высокая) и (гибкость = высокая) и (схема = слабоструктурированная),
то (приоритет документоориентированной архитектуры = высокий).
Использование таких правил позволяет реализовать гибкие экспертные системы, адаптирующиеся под разные ситуации.
Искусственные нейронные сети в задачах выбора и классификации
Нейронные сети – это модели, способные к обучению на примерах, выявлению сложных нелинейных зависимостей между входами и выходами, а также к обобщению.
Применительно к выбору архитектуры БД нейросеть может быть обучена на исторических кейсах – случаях выбора той или иной архитектуры в реальных проектах. Тогда сеть научится:
– распознавать паттерны требований и условий эксплуатации, которым соответствует та или иная СУБД;
– принимать решения на основе неформализуемых взаимосвязей (например, сочетания «высокая скорость + частое изменение структуры»);
– адаптироваться к новым условиям за счет дообучения.
Архитектура нейронной модели
В простейшем виде архитектура может включать:
– входной слой: значения ключевых параметров (объем данных, формат, SLA, количество пользователей и т. д.);
– скрытые слои: нелинейные зависимости;
– выходной слой: вероятностная оценка целевого класса – типа архитектуры (например, RDBMS – 0.2, DocumentDB – 0.7, GraphDB – 0.1).
Для более точного прогнозирования можно использовать ансамбли моделей, градиентный бустинг, рекуррентные или трансформерные сети.
Гибридные интеллектуальные модели: нейро-нечеткие системы
Особый интерес представляют нейро-нечеткие модели, которые сочетают в себе объяснимость и знания из нечеткой логики с обучаемостью нейросетей.
Наиболее известной является архитектура ANFIS (Adaptive Neuro-Fuzzy Inference System). Она использует нечеткие правила в явном виде, автоматическое обучение параметров функций принадлежности и весов, высокую интерпретируемость
и способность обрабатывать как лингвистические, так и численные входы [6–9].
Преимущества нейро-нечетких моделей:
– обучаемость + объяснимость: модель можно обучить на данных и в то же время интерпретировать ее поведение через нечеткие правила;
– гибкость: возможность адаптироваться под особенности конкретного проекта;
– модульность: возможна настройка под специфические критерии (например, встраивание SLA или политики безопасности).
Система также может показать наиболее сработавшие правила, например:
Если (гибкость = высокая) и (запись = высокая), то (приоритет DocumentDB = высокий).
Проектирование модели выбора архитектуры баз данных с использованием нечеткой логики и нейросетей
Цель проектирования модели – разработать интеллектуальную систему поддержки принятия решений (СППР), способную автоматически рекомендовать архитектурные решения для хранения
и обработки разнородных данных. При этом особое внимание уделяется:
– учету неопределенности и вариативности входных параметров;
– многокритериальной природе архитектурного выбора;
– автоматизируемости и адаптивности системы к различным сценариям;
– интерпретируемости результатов и прозрачности логики выбора.
Задачи, решаемые в рамках проектирования:
– формализация требований и ограничений к архитектуре БД;
– выделение ключевых критериев, влияющих на архитектурное решение;
– проектирование гибридной модели, сочетающей нечеткую логическую систему и нейросетевую адаптацию;
– разработка алгоритма обработки входных данных и принятия решения;
– предварительная валидация корректности и обоснованности рекомендаций модели.
Входные параметры модели
Модель принимает на вход вектор характеристик
системы X = (x1, x2, ..., x), где каждый параметр xᵢ соответствует одной из характеристик проектируемой системы. Основные параметры включают:
– x1 – объем данных, GB: количественная оценка предполагаемого объема хранимой информации. Диапазон значений: [10, 106] GB;
– x2 – структурность данных (безразмерная): характеризует степень упорядоченности данных. Значения: 0 (неструктурированные), 0,5 (полуструктурированные), 1 (структурированные);
– x3 – нагрузка на чтение/запись (запросов/с): интенсивность операций. Диапазон: [1, 105] запросов/с;
– x4 – связность данных (безразмерная): степень взаимосвязи между сущностями. Значения: [0, 1], где 0 – отсутствие связей, 1 – высокосвязные данные (графовая структура);
– x5 – требования к транзакциям (безразмерная): потребность в ACID-гарантиях. Значения: 0 (не требуется), 0,5 (частично), 1 (строгие ACID);
– x6 – скорость роста данных (%/мес): темп прироста объема. Диапазон: [0, 100] %/мес.
Функции принадлежности нечетких множеств
Для каждого входного параметра определены функции принадлежности к лингвистическим переменным. Используются трапециевидные и треугольные функции принадлежности, обеспечивающие плавные переходы между категориями.
Параметр x1: объем данных:
Малый объем: μ малый (x1) =

Параметр x2: структурность данных.
Параметр характеризует степень упорядоченности и формализации структуры данных. Значения: [0, 1], где 0 – полностью неструктурированные данные (текст, видео); 0,5 – полуструктурированные (JSON, XML); 1 – строго структурированные (реляционные таблицы).
Низкая структурность (неструктурированные данные):
μ низкая (x2) =
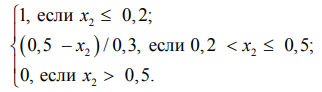
Средняя структурность (полуструктурированные данные):
μ средняя (x2) =
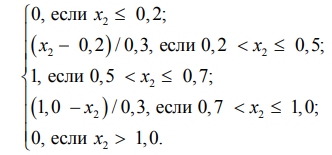
Высокая структурность (строго структурированные данные):
μ высокая (x2) =

Параметр x3: нагрузка на чтение/запись.
Параметр характеризует интенсивность операций чтения и записи в системе. Измеряется в запросах в секунду (RPS – Requests Per Second). Диапазон значений: [1, 100 000] запросов/с.

Параметр x4: связность данных.
Параметр характеризует степень взаимосвязанности сущностей в системе, количество и важность связей между объектами данных. Значения: [0, 1], где 0 – данные изолированы (независимые документы); 1 – высокосвязные данные (графовые структуры, социальные сети).
Низкая связность (слабо связанные данные):
μ низкая (x4) =

Параметр x5: требования к транзакциям.
Параметр характеризует необходимость поддержки ACID-гарантий (Atomicity, Consistency, Isolation, Durability) в системе. Значения: [0, 1], где
0 – транзакционность не требуется (eventual consistency); 0,5 – частичная транзакционность; 1 – строгие ACID-гарантии.
Низкие требования (eventual consistency):
μ низкие (x5) =
Параметр x6: скорость роста данных.
Параметр характеризует темп прироста объема данных в системе. Измеряется в процентах прироста в месяц. Диапазон значений: [0, 100] %/мес.
Низкая скорость роста (стабильный объем):
μ низкая (x6) =

Средняя скорость роста:
μ средняя (x6) =

Архитектура гибридной нейро-нечеткой модели
Предложенная модель состоит из трех основных уровней, реализующих последовательную обработку входных данных:
Уровень 1. Фаззификация входных данных.
Нормализованные значения параметров X преобразуются в степени принадлежности к лингвистическим термам:
μij = μi(xᵢ), где i = 1, ..., n, j {низкий, средний, высокий}.
Уровень 2. Нечеткий логический вывод (метод Мамдани).
Применяются продукционные правила типа
IF–THEN:
Rk: IF x1 is A1k AND x2 is A2k AND ... AND xn is Ank THEN y is Bk,
где Aᵢk – лингвистические термы входных параметров; Bk – выходной терм (рекомендуемая архитектура БД); k = 1, ..., M (общее количество правил).
Степень активации правила Rk вычисляется по оператору минимума (T-норма):
αk = min(μ1k(x1), μ2k(x2), ..., μnk (xn)).
Агрегация выходов всех правил выполняется по оператору максимума (S-норма):
μₒᵤt(y) = maxk(min(αk, μBk(y))).
Дефаззификация выполняется методом центра тяжести (Center of Gravity):
yfuzzy = ∫ y · μₒᵤt(y) dy / ∫ μₒᵤt(y) dy.
Уровень 3. Нейросетевая коррекция.
Для повышения точности модели применяется нейросетевой компонент, обученный на исторических данных о реализованных проектах. Архитектура нейросети: многослойный персептрон (MLP)
с двумя скрытыми слоями:
– входной слой: n нейронов (по числу параметров);
– скрытый слой 1: 64 нейрона, функция активации ReLU;
– скрытый слой 2: 32 нейрона, функция активации ReLU;
– выходной слой: 5 нейронов (по числу типов архитектур БД), функция активации softmax.
Коррекция выходного значения:
Δy = NN(X; θ);
yfinal = wfuzzy yfuzzy + wNN Δy,
где θ – параметры нейросети (веса и смещения), обучаемые методом обратного распространения ошибки; wfuzzy и wNN – весовые коэффициенты, определяющие вклад нечеткой и нейросетевой подсистем соответственно (wfuzzy + wNN = 1).
Финальный выход модели представляет собой вектор вероятностей P = (prel, pdoc, pgraph, pcol, phybrid), где каждый компонент pᵢ [0, 1] характеризует степень предпочтительности соответствующей архитектуры: реляционной (Relational), документоориентированной (Document), графовой (Graph), колоночной (Columnar) или гибридной (Hybrid).
Алгоритм работы модели
Процесс принятия решения о выборе архитектуры базы данных формализован в виде следующего алгоритма.
Вход: вектор характеристик системы X = (x1, x2, ..., x).
Выход: вектор вероятностей архитектур P = (prel, pdoc, pgraph, pcol, phybrid).
Шаг 1. Нормализация входных данных.
Для каждого параметра xᵢ выполнить нормализацию в диапазон [0, 1]:
xᵢ norm = (xᵢ − xᵢ min) / (xᵢ max − xᵢ min).
Шаг 2. Фаззификация.
Для каждого параметра xᵢ и каждого лингвистического терма Aj вычислить степень принадлежности:
μᵢj = μ(xᵢ norm).
Шаг 3. Применение правил нечеткого вывода.
Для каждого правила Rk (k = 1, ..., M):
3.1. Вычислить степень активации правила:
αk = min(μ1k, μ2k, ..., μnk).
3.2. Применить степень активации к выходному терму Bk:
μk out(y) = min(αk, μBk(y)).
Шаг 4. Агрегация выходов.
Объединить выходные функции принадлежности всех правил по оператору максимума:
μₒᵤt(y) = maxk(μk out(y)).
Шаг 5. Дефаззификация.
Получить четкое значение выхода методом центра тяжести:
yfuzzy = ∑ yᵢ · μₒᵤt(yᵢ) / ∑ μₒᵤt(yᵢ).
Шаг 6. Нейросетевая коррекция.
Подать нормализованный вектор X на вход обученной нейросети:
h = ReLU(W1X + b1);
h = ReLU(W2h1 + b2);
Δy = softmax(W3h2 + b3).
Шаг 7. Формирование итогового решения.
Объединить выходы нечеткой и нейросетевой подсистем:
P = normalize(wfuzzy · yfuzzy + wNN · Δy).
Шаг 8. Ранжирование и выбор архитектуры.
Упорядочить компоненты вектора P по убыванию вероятности. Архитектура с наибольшим значением pᵢ рекомендуется как оптимальная для заданных условий. При необходимости предоставить пользователю топ-3 рекомендации с указанием вероятностей.
Экспериментальная установка
Формирование датасета. Для обучения и тестирования модели был создан синтетический датасет на основе экспертной оценки 500 реальных проектов информационных систем различного масштаба и назначения. Датасет включает следующие категории проектов:
– корпоративные информационные системы (ERP, CRM) – 120 проектов;
– системы электронной коммерции и веб-приложения – 95 проектов;
– аналитические платформы и хранилища данных – 80 проектов;
– IoT-системы и системы реального времени – 75 проектов;
– социальные сети и системы управления контентом – 70 проектов.
Для каждого проекта были зафиксированы значения шести входных параметров (объем данных, структурность, нагрузка, связность, требования к транзакциям, скорость роста) и экспертно определена оптимальная архитектура БД. Датасет был разделен в соотношении 70 : 15 : 15 на обучающую, валидационную и тестовую выборки соответственно.
Параметры обучения нейросетевого компонента:
– оптимизатор: Adam (learning rate = 0,001, β1 = 0,9, β2 = 0,999);
– функция потерь: Categorical Cross-Entropy;
– размер мини-батча: 32;
– количество эпох: 100 (с ранней остановкой при отсутствии улучшения на валидационной выборке в течение 15 эпох);
– регуляризация: Dropout (p = 0,3) и L2-регуляризация (λ = 0,001).
Весовые коэффициенты интеграции: w_fuzzy = 0,6, w_NN = 0,4. Соотношение выбрано на основе кросс-валидации и отражает больший вес интерпретируемой нечеткой компоненты при сохранении адаптивности нейросети.
Аппаратное обеспечение: эксперименты проводились на сервере с процессором Intel Xeon E5-2680 v4 (2.4 GHz, 14 ядер), 64 GB RAM, GPU NVIDIA Tesla V100 (16 GB).
Результаты классификации архитектур баз данных
Точность модели на тестовой выборке составила 89,3 %, что значительно превосходит базовые подходы (табл. 1).
Таблица 1
Table 1
Сравнение точности предложенной модели с базовыми подходами
Comparison of the accuracy of the proposed model with basic approaches
|
Подход |
Accuracy, % |
Precision, % |
F1-score, % |
|
Экспертная оценка (человек) |
76,4 |
74,2 |
75,1 |
|
Правила на основе порогов |
68,7 |
65,3 |
66,8 |
|
Только нечеткая логика |
82,1 |
80,5 |
81,2 |
|
Только нейросеть (MLP) |
85,6 |
83,9 |
84,7 |
|
Предложенная гибридная модель |
89,3 |
88,1 |
88,6 |
Предложенная гибридная модель превосходит все базовые подходы (см. табл. 1). Прирост точности относительно чисто нечеткого подхода составил 7,2 %, относительно нейросетевого – 3,7 %, что статически значимо (p < 0,01, критерий Макнемара). В табл. 2 представлены детальные метрики качества для каждого типа архитектуры БД.
Таблица 2
Table 2
Метрики качества по типам архитектур БД
Quality metrics by type of database architectures
|
Тип архитектуры |
Precision, % |
Recall, % |
F1-score, % |
Поддержка |
|
Реляционная |
92,1 |
90,5 |
91,3 |
21 |
|
Документоориентированная |
88,7 |
87,2 |
87,9 |
18 |
|
Графовая |
85,3 |
89,1 |
87,2 |
11 |
|
Колоночная |
87,5 |
86,7 |
87,1 |
15 |
|
Гибридная |
83,9 |
82,4 |
83,1 |
10 |
|
Макро-среднее |
88,1 |
87,2 |
88,6 |
75 |
Разработанная нейро-нечеткая модель демонстрирует высокую точность для всех типов архитектур (см. табл. 2). Наилучшие результаты достигнуты для реляционных БД (F1 = 91,3 %), что объясняется их широким представлением в обучающей выборке и четко выраженными характеристиками. Гибридные архитектуры классифицируются с несколько меньшей точностью (F1 = 83,1 %) ввиду их многообразия и сложности определения границ.
Разработанная нейро-нечеткая модель корректно определяет оптимальную архитектуру для различных типовых сценариев, при этом уровень уверенности (вероятность) коррелирует с однозначностью входных характеристик (табл. 3).
Таблица 3
Table 3
Примеры работы разработанной нейро-нечеткой модели на типовых сценариях
Examples of how the proposed neuro-fuzzy model works in typical scenarios
|
Сценарий |
Характеристики |
Рекомендация |
Вероятность |
|
Корпоративная ERP |
Объем: 500 GB. Структурность: 0,95. |
Реляционная |
0,93 |
|
Система IoT |
Объем: 50 TB. Структурность: 0,3. |
Колоночная |
0,88 |
|
Социальная сеть |
Объем: 10 TB. Связность: 0,92. |
Графовая |
0,91 |
|
Электронная |
Объем: 5 TB. Структурность: 0,6. |
Документо-ориентированная |
0,86 |
|
Аналитическая платформа |
Объем: 100 TB. Структурность: 0,7. |
Гибридная |
0,82 |
Анализ ошибок классификации
Для детального анализа работы модели была построена матрица ошибок (confusion matrix), представленная в табл. 4 (жирным шрифтом выделены диагональные элементы матрицы, соответствующие корректным предсказаниям модели).
Таблица 4
Table 4
Матрица ошибок классификации (тестовая выборка, n = 75)
Classification error matrix (test sample, n = 75)
|
Факт Прогноз |
Реляционная |
Документо-ориентированная |
Графовая |
Колоночная |
Гибридная |
|
Реляционная |
19 |
1 |
0 |
0 |
1 |
|
Документо-ориентированная |
1 |
15 |
0 |
1 |
1 |
|
Графовая |
0 |
1 |
10 |
0 |
0 |
|
Колоночная |
0 |
1 |
0 |
13 |
1 |
|
Гибридная |
1 |
0 |
1 |
0 |
8 |
Анализ матрицы ошибок показывает, что большинство ошибок модели связано с классификацией гибридных архитектур, которые по своей природе находятся на границе нескольких типов. Путаница между реляционными и документоориентированными БД встречается редко (2 случая из 75), что свидетельствует о четкой дифференциации модели между принципиально различными типами архитектур. Время классификации одного объекта составляет в среднем 12,3 мс (на CPU) и 2,7 мс (на GPU), что позволяет использовать модель в интерактивных системах поддержки принятия решений. Время обучения нейросетевого компонента на полном датасете (350 примеров) составило 7,4 минуты на GPU, что делает возможным регулярное переобучение модели при появлении новых данных. Полученные результаты подтверждают эффективность гибридного подхода, сочетающего нечеткую логику и нейросетевой анализ. Преимущество предложенной модели перед чисто нечеткими системами обусловлено способностью нейросетевого компонента к обучению на эмпирических данных и адаптации к изменяющимся условиям. В то же время превосходство над чисто нейросетевым подходом объясняется включением экспертных знаний в виде нечетких правил, что повышает обобщающую способность модели и снижает требования к объему обучающих данных.
Модель, основанная на нечеткой логике, может быть применена в различных практических сценариях. Она полезна для анализа проектов на этапе проектирования архитектуры, когда необходимо объективно оценить множество факторов при выборе СУБД. Также она может служить инструментом поддержки архитекторов и тимлидов при принятии архитектурных решений, снижая влияние субъективности и усиливая обоснованность выбора. В образовательной сфере модель может использоваться в обучающих системах для студентов и инженеров, помогая им понять взаимосвязи между требованиями и архитектурными решениями. При миграции между базами данных модель позволяет провести оценку новой архитектуры с учетом текущих условий и требований, снижая риски перехода. В рамках DevOps и DevSecOps практик модель может применяться для оценки совместимости выбранной СУБД с существующей инфраструктурой, а также для выбора наиболее устойчивых и адаптивных решений [10, 11].
Ограничения проектной модели:
– не учитывает экономические параметры напрямую (стоимость лицензий, TCO);
– требует качественной базы знаний и кейсов для обучения;
– может не учитывать специфические особенности СУБД на уровне реализации;
– точность модели зависит от полноты и качества правил, а также репрезентативности обучающей выборки.
Заключение
Предложена и теоретически обоснована модель выбора архитектуры баз данных для хранения и обработки разнородных, динамически изменяющихся данных, с учетом ключевых аспектов современной информационной среды: гетерогенности, масштабируемости, неопределенности и требования к высокой адаптивности. Сформулированы требования к интеллектуальной системе поддержки принятия решений (СППР) по выбору архитектуры баз данных, основанные на комплексном анализе типов обрабатываемых данных, системных требований и характеристик выполняемых операций. Разработана иерархия критериев, влияющих на архитектурный выбор, которая включает такие параметры, как структурность данных, объем и масштабируемость, характер операций (чтение/запись), нагрузка, требования к транзакционности и связность данных. Обоснована необходимость применения гибридного подхода, сочетающего возможности нечеткой логики и нейросетевой адаптации. Нечеткая логика используется для обработки лингвистических, слабо формализуемых входных параметров, а нейросетевая составляющая – для обучения модели на эмпирических данных, автоматической настройки параметров и повышения точности решений в условиях неполноты или изменчивости информации. Предложена структурная архитектура гибридной модели, включающая модуль нормализации и фаззификации входных данных, блок нечеткого логического вывода на основе заданных правил, корректирующую нейросетевую подсистему и модуль интерпретации с визуализацией результатов. Представлены примеры формализации экспертных правил, типов входных данных, функций принадлежности и логики принятия решений, а также код, демонстрирующий принцип функционирования всей модели. Описаны потенциальные сценарии применения системы, охватывающие поддержку архитекторов и проектировщиков на этапах проектирования, миграционные процессы между СУБД, обучение студентов и инженеров, а также выполнение предварительной аналитики при разработке сложных ИТ-систем.
С теоретической точки зрения данная работа развивает область проектирования интеллектуальных систем в следующих направлениях:
– демонстрирует синергетический эффект от объединения эвристических методов (нечеткая логика) и обучаемых моделей (нейросети);
– расширяет применение нечетких моделей в сфере системной архитектуры и проектирования БД, выходя за рамки классических задач распознавания и контроля;
– подкрепляет концепцию интерпретируемого ИИ – предлагается модель, объясняющая свои решения в форме понятных пользователю правил и весов.
Практическая значимость предложенной модели заключается в ее потенциале для создания прототипа экспертной системы, способной автоматически выбирать оптимальные СУБД и архитектурные решения на основе заданных параметров и условий. Это позволяет существенно повысить качество проектных решений, особенно на ранних этапах разработки, когда отсутствуют полные данные о будущих нагрузках и объемах. Модель способствует снижению зависимости от субъективных экспертных оценок, обеспечивая более обоснованный и воспроизводимый выбор архитектуры. Кроме того, она может быть интегрирована в существующие инструменты проектирования и сопровождения архитектур, такие как CI/CD пайплайны, аналитические панели или компоненты DevOps-инфраструктуры, тем самым расширяя их функциональность и повышая общую эффективность процессов принятия решений в ИТ-проектах.
Работа открывает широкое поле для будущих исследований и практических реализаций:
1. Разработка прототипа и программная реализация:
– реализация модели в виде программного модуля (например, на Python с использованием Scikit-Fuzzy, PyTorch, Keras);
– создание веб-интерфейса или API для доступа к модели архитекторами/аналитиками.
– моделирование более сложных связей между критериями;
– использование динамической генерации правил из данных и экспертных сессий;
– интеграция методов автоматического извлечения знаний (например, через алгоритмы Rule Induction или Symbolic Regression).
3. Уточнение нейросетевой подсистемы:
– применение глубоких архитектур (например, GNN для графов входных параметров);
– обучение на синтетических и реальных данных из практики крупных ИТ-проектов;
– применение объяснимого машинного обучения (XAI) для интерпретации вкладов критериев.
4. Адаптация модели под конкретные отрасли:
– под BI/аналитику, финтех, IoT, системы реального времени;
– разработка отраслевых «профилей архитектуры» и соответствующих подмножеств правил.
5. Интеграция с системами управления знаниями и документооборотом:
– использование модели как части большой экспертной среды, хранящей кейсы, решения, выводы и обоснования;
– возможность обогащать модель в процессе эксплуатации – самообучающаяся архитектурная платформа.
На следующем этапе целесообразно сосредоточиться на апробации модели на практике, создании открытой библиотеки правил и запуске прототипа, который станет полезным инструментом в арсенале специалистов по проектированию и эксплуатации информационных систем.
1. Islam M. A., Anderson D. T., Pinar A. J., Havens T. C., Scott G., Keller J. M. Enabling Explainable Fusion in Deep Learning with Fuzzy Integral Neural Networks. IEEE Transactions on Fuzzy Systems, 2020, vol. 28, no. 7, pp. 1291-1300. DOIhttps://doi.org/10.1109/TFUZZ.2019.2917124.
2. Aggoune A. Intelligent data integration from hetero-geneous relational databases containing incomplete and uncertain information. Intelligent Data Analysis, 2022, vol. 26, no. 1, pp. 75-99. DOIhttps://doi.org/10.3233/IDA-205535.
3. Min K., Jananthan H., Kepner J. Fuzzy Relational Databases via Associative Arrays. 2024 IEEE High Perfor-mance Extreme Computing Conference (HPEC). IEEE, 2024, pp. 1-7. DOIhttps://doi.org/10.1109/HPEC62836.2024.10534916.
4. de Campos Souza P. V. Fuzzy neural networks and neuro-fuzzy networks: A review of the main techniques and applications used in the literature. Applied Soft Computing, 2020, vol. 92, article 106275. DOIhttps://doi.org/10.1016/j.asoc.2020.106275.
5. Ojha V., Abraham A., Snášel V. Heuristic design of fuzzy inference systems: A review of three decades of research. Engineering Applications of Artificial Intelligence, 2019, vol. 85, pp. 845-864. DOIhttps://doi.org/10.1016/j.engappai.2019.08.010.
6. Ahmad A., Rudrusamy G., Budiarto R., Samsudin A., Ramadass S. A Hybrid Rule Based Fuzzy-Neural Expert System for Passive Network Monitoring. Proceedings of the Arab Conference on Information Technology (ACIT). Dhaka, 2002. Pp. 746-752.
7. Yarushkina N., Moshkin V., Andreev I., Klein V., Beksaeva E. Hybridization of fuzzy inference and self-learning fuzzy ontology-based semantic data analysis. Proceedings of the First International Scientific Conference “Intelligent Information Technologies for Industry” (IITI'16). Sochi, Springer, 2016. Pp. 277-285.
8. Jiyad A. M., Nemer Z. N. A Hybrid Fuzzy-Neural Network Approach for Advanced Pattern Recognition and Predictive Analytic. Journal of Information Systems Engi-neering and Management, 2025, vol. 10, no. 32s. DOIhttps://doi.org/10.52783/jisem.v10i32s.5183.
9. Al-Ashoor A., Lilik F., Nagy S. A Systematic Analy-sis of Neural Networks, Fuzzy Logic and Genetic Algo-rithms in Tumor Classification. Applied Sciences, 2025, vol. 15, no. 9, article 5186. DOIhttps://doi.org/10.3390/app15095186.
10. Martinez-Cruz C., Noguera J. M., Vila M. A. Flexible queries on relational databases using fuzzy logic and ontologies. Information Sciences, 2016, vol. 366, pp. 150-164. DOIhttps://doi.org/10.1016/j.ins.2016.05.038.
11. Moura B., Soares Y., Sampaio L., Reiser R., Pilla M., Yamin A. fGrid: Uncertainty Variables Modeling for Computational Grids using Fuzzy Logic. 2016 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). Vancouver, IEEE, 2016. Pp. 2249-2256. DOIhttps://doi.org/10.1109/FUZZ-IEEE.2016.7737973.
