











Россия
Астрахань, Россия
Россия
Россия
Приведены сведения о росте интереса к технологиям ситуационной видеоаналитики (СВА) в различных областях деятельности. Описана тенденция к реализации систем СВА на базе когнитивных технологий искусственного интеллекта, позволяющих с высокой степенью точности обнаружить объект и его расположение в видеопотоке в режиме реального времени. Предложена архитектура системы поддержки принятия решений (СППР) с возможностью многообъектного распознавания. Выделены ключевые логические компоненты СППР в области СВА, а также описаны функции и назначение каждого компонента. Особо отмечена роль лица, принимающего решения, для реализации многообъектного распознавания при поиске объекта в видеопотоке. Приведена классификация нейронных сетей по типам и областям применения, выявлено, что именно сверточные нейронные сети применяются для решения задач видеоаналитики. Рассмотрены примеры использования сверточной модели YOLOv5 в системе управления базами моделей СППР в задачах СВА для выявления присутствия объектов на видеоданных. Разработана блок-схема алгоритма распознавания объектов СВА. Проведена серия экспериментов по обучению модели сверточной нейронной сети на уникальном наборе данных, на расширенном наборе данных и с новым дополнительным объектом. Такая организация экспериментов направлена на повышение качества и точности распознавания объектов и исследование возможности многообъектного распознавания. В результате эксперимента была протестирована финальная обученная модель нейронной сети и проведен анализ ее потенциальных возможностей для использования в СППР СВА с учетом показателя точности модели. Точность составила 91,6 % для валидационного набора, содержащего 2 объекта. Полученные результаты с использованием обученной нейронной сети архитектуры YOLOv5 подтверждает значимость сверточных нейронных сетей как ключевого компонента базы моделей СППР СВА.
система поддержки принятия решений, видеонаблюдение, ситуационная видеоаналитика, нейронные сети, искусственный интеллект, распознавание объектов, метрики точности, YOLOv5
Введение
Последнее десятилетие характеризуется стремительным ростом объема данных: в 2023 г. объем генерируемых данных оценивается в 120 зеттабайт (ежедневно создается около 330 млн терабайт данных), а в 2025 г. прогнозируется его увеличение в 1,5 раза, до 181 зеттабайт [1]. Значительную часть этих данных составляют видеоданные, генерируемые видеокамерами. В 2023 г. число камер видеонаблюдения в России составило 23,4 млн. Прогнозируется, что в период до 2028 г. объем российского рынка видеонаблюдения будет расти на 10–12 %
в год и достигнет 24 млрд руб. [2]. Задачи видеонаблюдения можно классифицировать на следующие основные направления: распознавание лиц, распознавание государственных регистрационных номеров автомобилей, ситуационная видеоаналитика (охрана, мониторинг, контроль за детьми, пожилыми родственниками), видеоаналитика в ритейле (рис. 1).
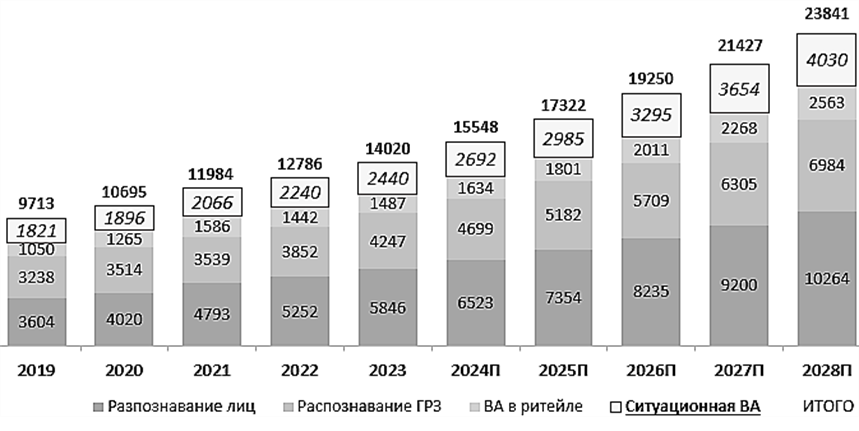
Рис. 1. Структура рынка видеоаналитики в России по видам, млн руб. [2]: П – прогноз
Fig. 1. The structure of the video analytics market in Russia by type, million rubles [2]: П – forecast
Ситуационная видеоаналитика (СВА) эволюционировала от классических детерминированных алгоритмов обработки изображений к когнитивным технологиям на базе искусственного интеллекта, позволяющим восстанавливать контекст происходящего на сцене видеонаблюдения [3]. Современные технологии СВА должны обеспечивать не только распознавание на основе нейронных сетей заранее заданных объектов, но и динамическое обновление алгоритмов в ответ на изменяющиеся требования. Данные требования приводят к необходимости многообъектного распознавания в задачах СВА на основе интеграции обучаемых моделей искусственного интеллекта, способных адаптироваться к новым объектам и сценам видеонаблюдения. Помимо возможности добавления новых объектов, важно улучшать качество и точность сигнатур, являющихся критически важными для успешного детектирования объектов. Технологии СВА должны учитывать множество факторов: изменения в освещении, фоновый шум, искажения изображения и пр. Использование методов глубокого обучения нейронных сетей позволяет повысить качество распознавания, минимизируя количество ложных срабатываний и увеличивая скорость обработки данных.
В последние годы появились работы российских авторов в области СВА на основе нейронных сетей в различных сферах деятельности, включая транспорт [4], ритейл [5], службы безопасности [6] и пр. [7, 8]. В рассматриваемых публикациях предложены отдельные модули или сервисы программного обеспечения СВА [9], а также системы поддержки принятия решений СВА на нечетких моделях [10], однако не приводятся детальные результаты экспериментов с нейронными сетями и не рас-
смотрена структура систем поддержки принятия решений (СППР) в области СВА на основе нейронных сетей для многообъектного распознавания. Необходимость обработки непрерывно растущих объемов видеоинформации, многообъектного распознавания и поддержки принятия решений в условиях недостаточности человеческих ресурсов для их обработки определяет актуальность разработки соответствующих концептуальных решений в области СППР на основе инструментов обработки и аналитики видеоданных.
Конфигурация системы поддержки принятия решений для задач ситуационной видеоаналитики
Системы поддержки принятия решений СВА предполагают, что окончательное решение на сцене видеонаблюдения должно приниматься лицом, принимающим решения (ЛПР). Системы поддержки принятия решений должны включать в себя классические компоненты: систему управления базами данных (СУБД), систему управления базой моделей (СУБМ) и интерфейс пользователя, обеспечивающие высокий уровень адаптивности и функциональности систем [11]. База данных является одним из ключевых элементов СППР, обеспечивая хранение и доступ к необходимой информации, она включает в себя внутренние данные (данные о текущих ситуациях видеонаблюдения – видеоаналитика online и видеоархив) и внешние данные (сведения из внешних источников). База моделей включает в себя математические модели, позволяющие проводить анализ ситуаций с использованием различных когнитивных алгоритмов для получения полезной информации, помогающей в принятии решений [12]. В качестве основного компонента баз моделей СППР СВА будем рассматривать нейронные сети. Это связано со способностью нейронных сетей эффективно обрабатывать большие объемы данных и выявлять сложные закономерности, что делает их актуальными для использования в различных системах СВА в современных условиях [13].
Концептуальная структура СППР СВА, представленная на рис. 2, содержит несколько ключевых компонентов:
1. Интерфейсы подключения видеокамер обеспечивают подключение, настройку и получение видеопотоков информации с различных видеокамер.
2. Модуль первичной обработки видео осуществляет начальную обработку видеопотока, включая кодирование, сжатие и масштабирование изображений.
3. СУБМ СВА на основе нейронных сетей реализована на основе алгоритмов глубокого обучения и включает следующие компоненты:
– библиотека конфигураций нейронной сети хранит различные модели нейронных сетей;
– интерфейсы подключения к облачным сервисам СВА обеспечивают доступ к облачным вычислительным ресурсам;
– интерфейсы подключения внешних источников информации позволяют импортировать или экспортировать данные из других систем.
4. СУБД хранения и поиска данных по архиву видео и фото обеспечивает долгосрочное хранение данных и возможность быстрого доступа по загружаемому видеоконтенту.
5. СУБД хранения и поиска данных по архиву метаданных обеспечивают долгосрочное хранение видеоданных и изображений, а также выборку данных по дополнительной информации (метаданные) к объектам (описание, дата загрузки, теги и т. д.).
6. Модуль формирования отчетов и визуализации отвечает за создание отчетов и обеспечение визуализации результатов видеоанализа для предоставления ЛПР, которое может добавлять новые объекты СВА для детекции и определять вектор работы нейронной сети, тем самым реализуя возможность многообъектного распознавания в СВА
в режиме реального времени.
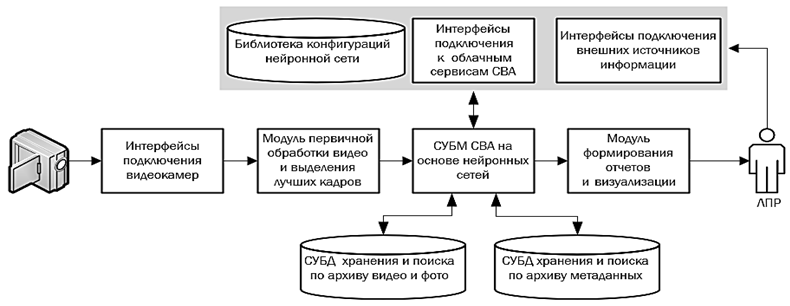
Рис. 2. Логические компоненты СППР СВА
Fig. 2. Logical components of the SVA DSS
Эффективность СППР СВА на основе нейронных сетей определяется совокупностью следующих факторов:
– большие объемы качественных видеоданных необходимы для обеспечения высокой точности и надежности нейронной сети;
– тип и архитектура нейронной сети имеют критическое значение, поскольку некорректный выбор этих параметров может привести к неспособности модели адекватно справляться с поставленными
задачами;
– конфигурация нейронной сети;
– требования к вычислительным ресурсам. Модели на основе нейронных сетей требовательны к вычислительным мощностям, включая мощные графические процессоры (GPU), что может стать препятствием для их внедрения в ряде организаций [14].
Классификация типов нейронных сетей и области их применения представлены на рис. 3 [14].

Рис. 3. Типы нейронных сетей и области их применения
Fig. 3. Types of neural networks and their applications
Сверточные нейронные сети (CNN) активно применяются для решения задач интеллектуального анализа видео. Они позволяют автоматически выделять признаки объектов в видеопотоке, что делает их идеальными для задач распознавания лиц, определения типа объектов и классификации видеоконтента [13, 15].
YOLOv5 (You Only Look Once version 5) представляет собой одну из последних конфигураций сверточных нейронных сетей (CNN) для распознавания объектов на основе глубокого обучения. Эта модель отличается высокой скоростью и точностью обнаружения объектов, что делает ее подходящим инструментом для задач, направленных на распознавание и детекции объектов СВА в режиме реального времени. YOLOv5 включает в следующие компоненты:
– магистраль (Backbone) использует модифицированную архитектуру CSP-Darknet53 для извлечения признаков из входного изображения. Эта часть предназначена для извлечения низкоуровневых и высокоуровневых признаков;
– шея (Neck) состоит из SPPF (Spatial Pyramid Pooling Fast) и CSP-PAN (Cross Stage Partial Path Aggregation Network). Эти блоки соединяют информацию из разных уровней магистрали и улучшают поток информации между ними;
– голова (Head) отвечает за окончательную детекцию объектов. Она использует YOLOv3 Head для предсказания координат ограничивающих рамок (bounding boxes), классов объектов и вероятности присутствия объектов в этих рамках.
YOLOv5 доступна в нескольких вариантах, включая YOLOv5s, YOLOv5m, YOLOv5l и YOLOv5x. Самая высокая скорость предсказания у YOLOv5 – до 140 кадров в секунду на мощных графических процессорах, таких как Tesla P100. Это значительно более высокий показатель скорости по сравнению с предыдущими версиями, такими как YOLOv4 (скорость предсказания 50 кадров в секунду) [16, 17].
Обучение сверточной модели нейронной сети требует тщательной подготовки данных, включая сбор, разметку и распределение согласно требованиям и рекомендациям создателей нейронной сети. Для успешного обучения и высокой точности определения расположения объектов обученной модели необходимо собрать достаточное количество изображений, на которых будут представлены объекты СВА, которые модель должна распознать в будущем. Для сбора данных предлагается использовать библиотеку Python ffmpeg, позволяющую кадрировать видеозапись. Дополнительные данные получены с помощью парсеров Google и Yandex картинок.
После сбора изображений необходимо аннотировать их, чтобы указать местоположение объекта и его класс. Для аннотации был выбран инструмент labelImg – приложение, написанное на Python и позволяющее создавать аннотации согласно требованиям YOLO. Аннотации к изображениям включают текстовые файлы с координатами ограниченных рамок (bounding boxes) и классами объектов. Каждый файл должен соответствовать одному изображению и содержать строки формата <class_id> <x_center> <y_center> <width> <height>.
После разметки необходимо подготовить данные для обучения согласно требованию к структуре. Данные следует разделить на обучающий набор и валидационный набор, в данном случае распределение было проведено в соотношении 70/30 (где 70 % – набор для обучения, а 30 % – набор для валидации). Важным шагом является создание конфигурационного файла «dataset.yaml», который будет содержать пути к обучающим и валидационным данным, а также имена классов.
Поиск объектов с использованием СППР для выявления требуемых объектов СВА на основе нейронных сетей происходит с участием ЛПР согласно блок-схеме, представленной на рис. 4.
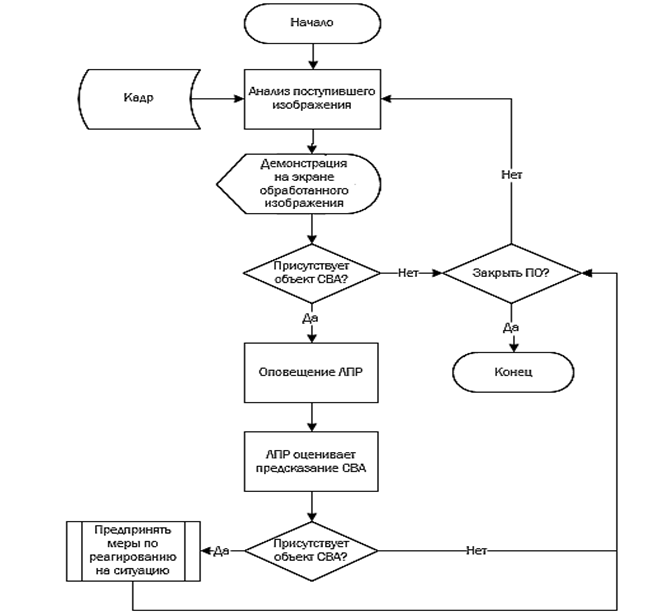
Рис. 4. Блок-схема алгоритма СППР для выявления объектов СВА
Fig. 4. A block diagram of the DSS algorithm for detecting SVA objects
В случае подачи сигнала оповещения об обнаружении объекта, схожего по форме представления с объектом СВА, ЛПР необходимо проанализировать данную ситуацию и принять решение в правильности предсказания нейронной сети. Если система не ошиблась, необходимо принять меры реагирования на ситуацию согласно регламенту организации, например закрыть все двери и вызвать полицию или передать сведения службе безопасности.
Планирование экспериментов исследования сверточной нейронной модели YOLOv5 для многообъектного распознавания
Рассмотрим некоторые примеры использования сверточной модели YOLOv5 в СУБМ СППР в задачах СВА для выявления присутствия объектов и их расположения на видеопотоке. Проведем оценку ее точности, производительности и потенциала присутствия как основной модели в базе моделей СППР СВА.
Исследование сверточной модели YOLOv5 было разделено на две основные части. В первой части проводилось обучение модели на изображениях людей на горнолыжных трассах, с последующим анализом точности и качества полученных моделей. Во второй части исследования была выбрана лучшая модель из первой части экспериментов, после чего был расширен набор изображений и аннотаций к ним и включен новый объект – оружие (пистолет). Данная манипуляция позволила продолжить обучение модели с использованием обновленных данных, что является важным шагом для возможности обнаружения нескольких объектов, используя одну модель YOLOv5.
Обучение модели: 1 часть эксперимента. Данные были разделены на 2 уникальных набора, где 1 318 изображений и аннотаций для обучения и 564 для валидации, в которых присутствовали изображения с объектами СВА. Данный подход позволяет не только обучить модель, но и оценить точность определения объектов на новых данных, которые
не использовались в процессе обучения. Валидационный набор данных играет ключевую роль в контроле предотвращения переобучения модели, позволяя вовремя заметить данный процесс и остановить обучение.
Обучение модели проводилось с помощью облачной платформы Colab.google, которая предоставляет необходимые мощности графической видеопамяти (GPU) и позволяет ускорить процесс обучения и достигнуть высокой точности при обучении модели нейронных сетей. Продолжительность обучения составила 26 часов и заняла 29 эпох. Каждая эпоха представляет собой полный проход по обучающему набору данных и перераспределение весов для обнаружения объекта СВА. Важно отметить, что после 28 эпохи началось переобучение модели, что проявилось в снижении точности на валидационных данных. Финальная модель достигла точности с показателем Precision = 95,2 %, расчеты проводились по формуле
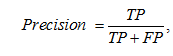
где TP (True Positives) – количество истинно положительных предсказаний (правильно обнаруженные объекты); FP (False Positives) – количество ложноположительных предсказаний (объекты, которые были ошибочно классифицированы как обнаруженные). Статистика эксперимента во время обучения приведена в табл. 1, где представлены ключевые метрики, помогающие оценить эффективность и качество обученной модели: box_loss – метрика измеряет ошибку в предсказании координат ограничивающих рамок, train – в обучаемом наборе данных, val – на валидационном наборе данных; obj_loss – объектная метрика измеряет вероятность наличия объекта в предсказанной рамке, train – в обучаемом наборе данных, val – на валидационном наборе данных; metrics/precision – метрика измеряет отношение правильно предсказанных положительных объектов к общему количеству предсказанных положительных объектов; metrics/recall – метрика измеряет долю правильно предсказанных положительных объектов к общему количеству реальных положительных объектов в тестовом наборе данных; metrics/mAP_0.5 – средняя точность при пороге IoU 0.5., показывающая насколько хорошо модель обнаруживает объекты
с заданным уровнем точности; metrics/mAP_0.5:0.95 – средняя точность при различных порогах IoU от 0.5 до 0.95 с шагом 0.05 (данная метрика предоставляет более полное представление о производительности модели, учитывая разные уровни строгости в оценке предсказаний).
Таблица 1
Table 1
Метрики точности модели во время обучения
Metrics of model accuracy during training
|
box_loss |
obj_loss |
metrics/precision |
metrics/recall |
metrics/mAP_0.5 |
metrics/mAP_0.5:0.95 |
|||||
|
train |
val |
train |
val |
|||||||
|
0 |
0,107 |
0,079 |
0,028 |
0,025 |
0,067 |
0,516 |
0,131 |
0,036 |
||
|
1 |
0,074 |
0,077 |
0,025 |
0,018 |
0,603 |
0,362 |
0,397 |
0,103 |
||
|
10 |
0,039 |
0,037 |
0,012 |
0,011 |
0,935 |
0,729 |
0,838 |
0,419 |
||
|
20 |
0,030 |
0,031 |
0,009 |
0,010 |
0,932 |
0,765 |
0,866 |
0,511 |
||
|
27 |
0,026 |
0,029 |
0,009 |
0,010 |
0,952 |
0,753 |
0,853 |
0,535 |
||
|
28 |
0,026 |
0,029 |
0,009 |
0,010 |
0,884 |
0,783 |
0,844 |
0,542 |
||
Финальная модель была протестирована на видеозаписи, кадры которой не участвовали в обучении и валидации моделей (рис. 5, а).
|
|
|
|
|
|
a |
б |
в |
|



Рис. 5. Результаты тестирования обученной модели нейронной сети архитектуры YOLOv5:
a – исходный набор данных (model 1); б – удвоенный набор данных (model 2); в – распознавание нового объекта
Fig. 5. Test results of the trained YOLOv5 neural network architecture model:
а – initial data set (model 1); б – doubled data set (model 2); в – recognition of a new object
Далее набор данных был удвоен, в него были также добавлены новые изображения, на которых объект отсутствует. Данная рекомендация предложена разработчиками YOLOv5 в официальной документации на GitHub [18]. После обновления набора данных было проведено дополнительное обучение, что позволило повысить точность до 96,7 % (см. рис. 5, б).
Помимо повышения точности, понизился процент ложных срабатываний на изображениях, где объект СВА отсутствовал. Сравнительный анализ обучения моделей с разным количеством набора данных представлен на рис. 6.
Финальная обученная модель YOLOv5, использующая уникальный набор данных, показала способность определять не только присутствие, но и отсутствие объектов (людей на горнолыжной трассе) на видеозаписях, которые не были представлены в процессе обучения модели.
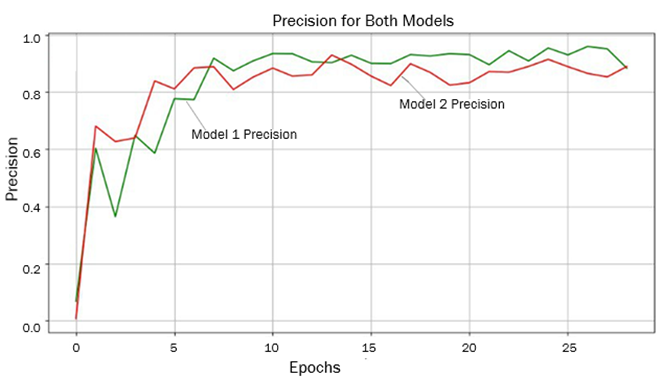
Рис. 6. Сравнительный анализ обучения моделей с разным количеством набора данных
Fig. 6. Comparative analysis of training models with different amounts of data set
Обучение модели: 2 часть эксперимента. Далее дополнительно был обогащен набор данных путем включения 500 новых изображений и соответствующих аннотаций к ним, содержащий только новый объект на изображениях – оружие (пистолет). Обучение продолжилось на финальной модели, полученной в первой части эксперимента, точность которой составила 96,7 %. Процесс обучения занял 37 часов и охватил 30 эпох, что позволило модели адаптироваться к новым данным. Статистические данные и результаты обучения модели представлены на рис. 7.
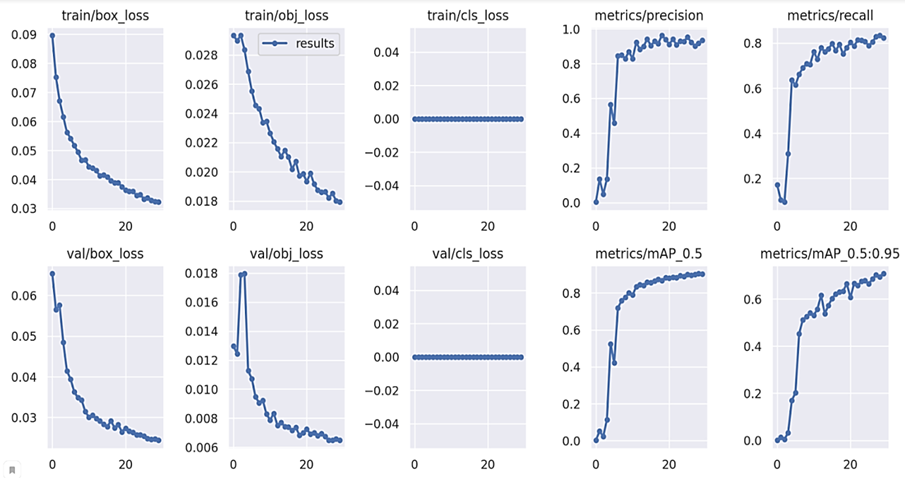
Рис. 7. Метрики обучения модели YOLOv5
Fig. 7. YOLOv5 model learning metrics
Следует отметить, что в итоге точность лучшей обученной модели на валидационных данных составила 91,6 % (табл. 2), что является снижением по сравнению с показателем точности первого эксперимента.
Таблица 2
Table 2
Метрики точности модели на валидационном наборе данных
Model accuracy metrics based on the validation dataset
|
Количество |
metrics/precision |
metrics/recall |
metrics/mAP_0.5 |
metrics/mAP_0.5:0.95 |
|
500 |
0,916 |
0,83 |
0,902 |
0,697 |
Снижение точности можно объяснить различием в объеме данных, использованных в первой и второй частях исследования, а также появлением дополнительного объекта. В первой части модель обучалась на однородном наборе изображений, тогда как во второй части эксперимента добавление нового объекта (пистолета) привело к увеличению сложности задачи распознавания.
Несмотря на снижение точности, финальная модель продемонстрировала высокую точность в распознавании двух объектов: человека на горнолыжной трассе и оружия (см. рис. 5, в). Данные результаты эксперимента подчеркивают способность YOLOv5 к многообъектному распознаванию в задачах СВА, когда необходимо идентифицировать несколько объектов одновременно.
Заключение
Разработана конфигурация СППР в области ситуационной видеоаналитики. В качестве основного типа моделей базы моделей СППР выбрана модель сверхточной нейронной сети. Выделены факторы, влияющие на эффективность СППР для задач СВА на основе нейронных сетей в современных условиях. Разработана блок-схема алгоритма СППР для выявления объектов СВА.
Собран уникальный набор данных и проведено исследование по обучению и тестированию модели сверточной нейронной сети для выявления ее качества и эффективности. Была проведена серия экспериментов. Результаты первого эксперимента показали точность 95,2 %, что является достаточно высоким значением, при этом наблюдались ложные срабатывания на изображениях, не участвовавших
в обучении. Далее набор данных был увеличен в два раза с помощью изображений и аннотаций к ним без объекта. Результаты второго эксперимента показали повышение точности модели до 96,7 %, а частота ложных срабатываний снизилась. Далее в набор данных были добавлены изображения с другим объектом. Обучение продолжилось на финальной модели, и точность ее составила 91,6 %. Увеличение набора данных, включая изображения, на которых объекты отсутствуют, привело к снижению процента ложных срабатываний при обработке видеокадров. Это подтверждает эффективность модели в распознавании объектов и подтверждает ее способность качественно срабатывать при появлении объекта в кадре, а также не выделять ошибочно ситуации, когда объект в кадре отсутствует. Добавление
в набор данных изображений и аннотаций к ним, содержащих другой объект, показывает возможность динамически менять сигнатуру к поиску новых объектов, при этом сохраняя и повышая точность выявления прежних объектов. Это делает возможным добавление новых объектов для детекции в ходе анализа видеоданных в соответствии с требованиями для многообъектного поиска объектов в СППР СВА. Полученные результаты показывают, что сверточные нейронные сети могут эффективно решать сложные задачи по поиску объекта на изображении в реальном времени, обеспечивая надежную поддержку для принятия обоснованных решений в критически важных ситуациях в организациях.
1. Рынок систем управления и обработки данных в Российской Федерации: текущее состояние и перспективы развития. URL: https://www.csr.ru/upload/iblock/26a/swogkcus54ne2jaqcn5r98cq8hiu4d3p.pdf (дата обращения: 30.10.2024).
2. ИАА TelecomDaily: в 2023 рынок ВА может вы-расти в два раза. URL: https://telecomdaily.ru/news/2022/06/16/iaa-telecomdaily-v-2023-rynok-va-mozhet-vyrasti-v-dva-raza (дата обращения: 30.10.2024).
3. ГОСТ Р 59385-2021. Информационные техноло-гии. Искусственный интеллект. Ситуационная видеоаналитика. Термины и определения. М.: Стандартинформ, 2021. 16 с.
4. Охотников А. Л. Ситуационная аналитика в системах технического зрения на железной дороге: термины и определения // Наука и технологии железных дорог. 2021. Т. 5. № 2 (18). С. 55–63.
5. Пузыревская А. В., Зитцер Д. К., Цыганова М. С. Модуль ситуационной видеоаналитики торгового зала // Математическое и информационное моделирование: материалы Всерос. конф. молодых ученых. Тюмень, 2024. С. 364–371.
6. Леонтьев В. Е., Кольцов А. С., Кобзистый С. Ю. Особенности применения ситуационной видеоаналитики на основе искусственных нейронных сетей в учреждениях ФСИН // Техника и безопасность объектов уголовно-исполнительной системы: cб. материалов Междунар. науч.-практ. конф. (Воронеж, 18–19 мая 2022 г.). Иваново: ИПК «ПресСто», 2022. С. 62–64.
7. Токарев В. Л., Абрамов Д. А. Система поддержки принятия решений задач ситуационной видеоаналитики // Современная наука: актуальные проблемы теории и практики. Сер.: Естественные и технические науки. 2016. № 6. С. 88–92.
8. Тельный А. В., Черников Р. С., Шаров В. А. Воз-можности использования ситуационной видеоаналитики // Шуйская сессия студентов, аспирантов, педагогов, молодых ученых: материалы ХIII Междунар. науч. конф. Шуя, 2020. С. 224–227.
9. Баженов Н. А., Пономарев В. А., Корзун Д. Ж. Создание архитектуры слоевой обработки видеоданных для сервисов ситуационной видеоаналитики // Цифровые технологии в образовании, науке, обществе: материалы XIV Всерос. науч.-практ. конф. Петрозаводск, 2020. С. 13–16.
10. Токарев В. Л., Абрамов Д. А. Система поддержки принятия решений задач ситуационной видеоаналитики // Современная наука: актуальные проблемы теории и практики. Сер.: Естественные и технические науки. 2016. № 6. С. 88–92.
11. Ларичев О. И., Петровский А. Б. Системы поддержки принятия решений: современные подходы и технологии. М.: Наука, 2020. 250 с.
12. Protalinskiy O., Andryushin A., Shcherbatov I., Khanova A., Urazaliev N. Strategic decision support in the process of manufacturing systems management // Proceed-ings of 2018 11th International Conference “Management of Large-Scale System Development”, MLSD 2018. 2018. P. 8551760.
13. Кузнецов И. П., Сидоров В. Н. YOLOv5: state-of-the-art модель для распознавания объектов. Neurohive. URL: https://neurohive.io/ru/papers/yolov5-state-of-the-art-model-dlya-raspoznavaniya-obektov/ (дата обращения: 17.11.2024).
14. Богданов А. В. Нейронные сети и их применение в задачах машинного обучения. М.: Физматлит, 2019. 320 с.
15. Черкасова И. С. Классификация видеоконтента на основе сверточных нейронных сетей // E-Scio. 2021. № 12 (63). С. 395–405.
16. Применение нейронных сетей в модулях аналитики Domination. URL: https://domination.one/press-center/articles/videoanalitika/primenenie-neyronnykh-setey-v-modulyakh-analitiki-domination/ (дата обращения: 17.11.2024).
17. Зейнетдинов Б. Г. Взгляд на YOLOv5 для распознавания объектов // Вопр. науки и образования. 2024. № 3 (175). С. 26–33.
18. Jocher G. YOLOv5 by Ultralytics. GitHub. URL: https://github.com/ultralytics/yolov5 (дата обращения: 20.10.2024).
