












Россия
Россия
Россия
Предложен подход к структурированию научных публикаций на примере научных работ по морскому автономному надводному судовождению, позволяющий провести интеллектуальный анализ данных с кластеризацией и визуализацией основных ключевых слов и словосочетаний, связанных с обозначенной тема-тикой. В качестве источника для получения данных использовался ресурс российской научной электронной биб-лиотеки eLIBRARY.RU. Собраны сведения по 534 релевантным научным публикациям за период с 2013 до начала 2024 года издания, содержащие название работы, год издания, список авторов и их аффилиацию, ключе-вые слова и словосочетания и т. д. Сформирована база данных для интеллектуального анализа, содержащая 1304 ключевых слова или словосочетания, указанных авторами научных публикаций как относящихся к выбранной тематике. Интеллектуальный анализ данных проведен с использованием пакета программного обеспечения с от-крытым исходным кодом для визуализации и анализа связанных данных Gephi, результаты обработки представ-лены в виде неориентированных графов. Приведены полученные неориентированные графы, а также указаны характеристики определенных графов при различных параметрах ядра. Выявлены кластеры ключевых слов или словосочетаний и связи между ними, демонстрирующие актуальные тенденции развития выбранного научного направления. С появлением новых научных публикаций по морскому автономному надводному судовождению графы будут изменяться, фиксируя новые связи между указываемыми авторами научных публикаций, ключевыми словами и словосочетаниями. Подобный подход к обработке данных может оказаться полезным студентам, аспирантам и научным работникам для выявления пула ключевых слов и словосочетаний, на которые необходимо обратить свое внимание при изучении указанной тематики.
интеллектуальный анализ, морское автономное надводное судно, неориентированный граф, кластер, автономное судовождение
Введение
Задачи разработки и применения автономных объектов в логистике, в сфере услуг, на транспорте, во многих производственных процессах в различных отраслях промышленности становятся все более популярными и востребованными, в том числе и в направлении создания морских автономных надводных судов (МАНС), в частности морских автономных и безэкипажных надводных судов. Данное направление в последние годы стало одним из стремительно развивающихся и перспективных, этой тематике посвящено значительное число научных исследований. К ним можно отнести и концепции создания и тестирования как МАНС, так и их элементов, и нормативно-правовые проблемы, которые возникают в процессе эксплуатации МАНС, причины возникновения такого рода проблем и ряд других. Большое внимание уделяется формированию международно-правовой системы регулирования деятельности и эксплуатирования МАНС, которую разрабатывает Международная морская организация, проводится анализ отечественного и зарубежного опыта подготовки операторов МАНС. Таким образом, растет круг тематик и число научных публикаций, посвященных МАНС. Ориентироваться в тематиках научных публикаций по автономному и безэкипажному судовождению с ростом их числа и разнообразия становится все сложнее. Соответственно, возникла насущная необходимость в использовании инструмента, который способен структурировать имеющиеся научные публикации, отражающие результаты научных исследований в областях, тесно связанных с тематиками по созданию, эксплуатации и тестировании автономных (в том числе безэкипажных) морских судов и других плавательных средств.
Для анализа связанных данных в настоящее время в тренде находится одно из перспективных направлений Data Science – графовые методы анализа. Такие методы анализа направлены на изучение взаимосвязей между различными объектами, в них исследуется структура графа и выявляются неочевидные зависимости. Эти методы не привязаны к широкому набору отраслей. Так, в работе [1] предлагается граф знаний по поиску библиотек ML/DL, оптимальных для пользовательских задач по выбранным критериям. В работе [2] описана сетевая графовая модель, способная прогнозировать тенденции фондового рынка, а в [3] – новый подход на основе графового анализа для классификации изображений с несколькими метками.
Наиболее популярными в настоящее время инструментами для графового анализа являются компонент GIGRAPH для Excel2016 и пакет программного обеспечения с открытым исходным кодом для визуализации и анализа связанных данных Gephi. Но если первый имеет серьезные ограничения по объему анализируемых данных и его можно рассматривать как инструмент оперативного анализа малого объема данных или репрезентативной выборки, то Gephi предоставляет более широкие возможности для анализа. Gephi является самым известным инструментом для визуализации графов и сетевого анализа и успешно используется для анализа больших данных, выгруженных из социальных сетей, мессенджеров, веб-сайтов [4–10]. При этом подход, связанный с анализом научных публикаций в Gephi, пока исследован недостаточно; например, одним из немногих исследований можно отметить работу автора [11], использующего данные из научной электронной библиотеки eLIBRARY.RU для анализа цитирований. Более подробно с возможностями Gephi можно ознакомиться по результатам работ [12, 13]. Дополнительно хотелось бы отметить, что сетевой метод исследования изучаемой предметной области при помощи визуализации связей между изучаемыми элементами помогает определить, в частности, скрытые и неочевидные связи. Выбранный пакет программного обеспечения имеет широкий набор инструментов и по методам исследования и визуализации анализа.
Формирование множества данных для проведения кластеризации
В качестве источника для получения данных использовался ресурс российской научной электронной библиотеки eLIBRARY.RU. Так, анализируя аннотации и, если возможно, открытые тексты научных публикаций, сформировано множество, содержащее данные по 534 научным публикациям, отобранным по тематике, связанной с автономными судами, автономным судоходством, в частности безэкипажными объектами водного транспорта. По каждой научной публикации зафиксированы название, год издания научной публикации, список авторов и их аффилиация, ключевые слова и словосочетания, указанные авторами к этой публикации, и ряд другой информации. Научные публикации рассматривались в период с 2013 до начала 2024 года издания (на рис. 1 указано распределение научных публикаций по годам издания). Таким образом, сформирована база данных для интеллектуального анализа, содержащая 1 304 ключевых слова или словосочетания, указанных авторами научных публикаций, относящихся к выбранной тематике.
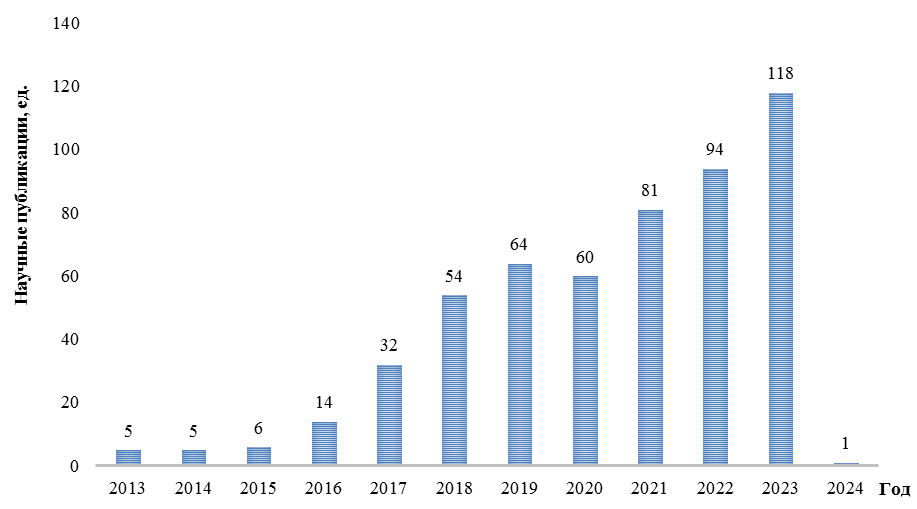
Рис. 1. Распределение научных публикаций по исследуемой тематике по годам
Fig. 1. Distribution of scientific publications by year
Сформированная таким образом база данных обрабатывалась средствами пакета программного обеспечения для сетевого анализа и визуализации с открытым исходным кодом под названием Gephi, способных графически визуализировать связи между объектами в анализируемой выборке.
Построение и анализ неориентированного графа по выделению кластеров ключевых слов и словосочетаний
Алгоритм построения неориентированного графа по выделению кластеров ключевых слов и словосочетаний подразумевает проведение следующих этапов. На первом этапе каждому из 1 304 ключевых слов или словосочетаний присваивается индивидуальный идентификационный номер от 1 до 1 304, т. е. таким образом формируется 1 304 узла неориентированного графа. На втором этапе для каждой научной публикации из множества в 534 научных публикаций фиксируются ребра, устанавливающие связь между ключевыми словами или словосочетаниями, которые были указаны авторами соответствующих научных публикаций. Таких неориентированных ребер образовалось 3 503. Заметим также, что в единственной публикации было указано одно ключевое словосочетание, поэтому получившиеся неориентированные графы содержат единственную петлю, т. е. неориентированное ребро из вершины в нее же саму. На третьем этапе осуществлялся выбор алгоритма формирования неориентированного графа и получения характеристик результатов работы алгоритмов. На четвертом этапе средствами пакета Gephi осуществляется кластерный анализ для выявления кластеров ключевых слов или словосочетаний, которые связаны между собой чаще всего.
Для анализа использовался метод укладки графов ForceAtlas 2 (отметим, что для этого примера алгоритмы ForceAtlas, Fruchterman Reingold, Noverlap и OpenOrd выдают аналогичные по характеристикам результаты) и параметр K-core (этот параметр указывает, сколько вершин неориентированного графа связано не менее чем с K вершинами графа), равный 8, чтобы исключить ключевые слова или словосочетания, которые реже всего встречаются в научных публикациях. Характеристики полученного неориентированного графа представлены в табл. 1. На основании коэффициента модулярности были определены кластеры в полученном графе, визуальное отображение которых иллюстрирует рис. 2.
Таблица 1
Table 1
Таблица характеристик полученного неориентированного графа при K-core, равном 8
The resulting undirected graph characteristics of with K-core equal to 8
|
№ характеристики |
Разновидность характеристики |
Характеристика |
Значение в полученном неориентированном графе |
|
1 |
Средняя степень |
Среднее число связей одного ключевого слова или словосочетания |
15,038 |
|
2 |
Cредняя взвешенная степень |
Среднее число связей узла, разделенное на общее число связей в графе |
30,615 |
|
3 |
Диаметр графа |
Параметр удаленности друг от друга двух максимально удаленных узлов неориентированного графа |
3 |
|
4 |
Плотность графа |
Отношение числа ребер к максимально возможному |
0,295 |
|
5 |
Модулярность |
Процент присутствия кластеров ключевого слова или словосочетания внутри графа |
0,225 |
|
6 |
Средний коэффициент кластеризации |
Степень взаимодействия между собой ближайших соседей узла, т. е. вероятность того, что ближайшие соседи узла будут связаны не только с ним, но и между собой |
0,578 |
|
7 |
Средняя длина пути |
Определяет среднее число ребер, которые можно пройти в связных компонентах |
1,715 |
Каждый кластер объединяет те ключевые слова или словосочетания, которые встречаются чаще всего в научных публикациях по заданной тематике. Каждому кластеру был присвоен определенный цвет. Каждой вершине был присвоен размер, зависящий от ее показателя PageRank – чем выше значение этого коэффициента, тем большим размером отображается данная вершина в визуализации. Самой крупной вершиной является вершина, соответствующая ключевому слову «безэкипажное судно» (здесь этот термин включает ключевое словосочетание как в единственном числе, так и во множественном).
Для упрощения восприятия информации на рис. 2 для каждого узла неориентированного графа выведены ключевые слова и словосочетания, расположенные таким образом, чтобы соседние узлы не мешали друг другу.
Приведем также распределение кластеров ключевых слов или словосочетаний, полученное методом Fruchterman Reingold, при этом также используем K-core, равный 8, чтобы исключить ключевые слова или словосочетания с низкой степенью повторяемости (рис. 3).
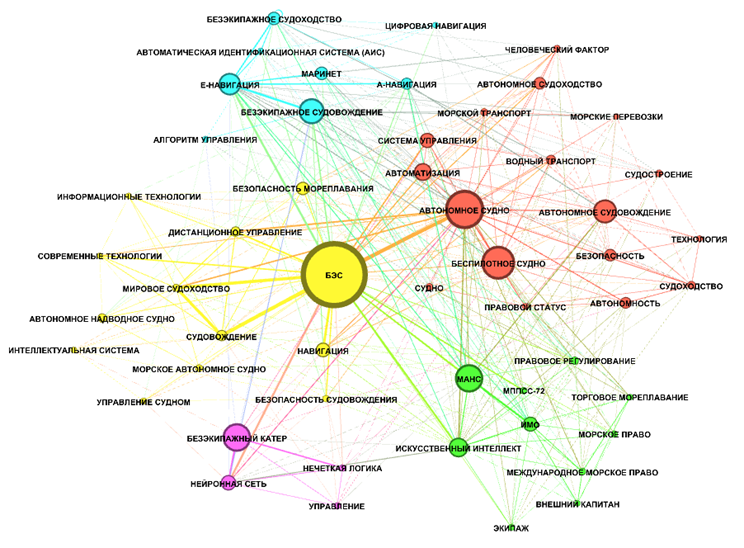
Рис. 2. Визуальное отображение полученных методом ForceAtlas 2 кластеров ключевых слов или словосочетаний, встречающихся чаще всего в научных публикациях по заданной тематике (5 кластеров)
Fig. 2. Visual display of 2 clusters of keywords or phrases obtained by the ForceAtlas method, found most often
in scientific publications on a given topic (5 clusters)
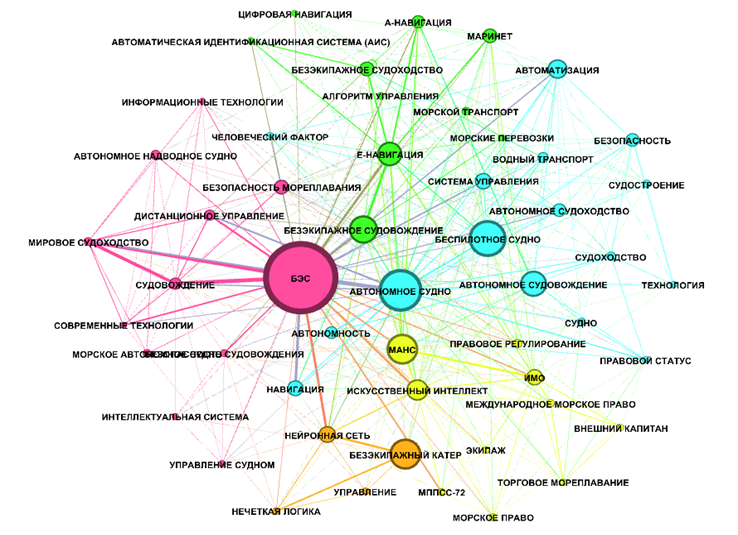
Рис. 3. Визуальное отображение полученных методом Fruchterman Reingold (при K-core, равном 8)
кластеров ключевых слов или словосочетаний
Fig. 3. Visual display of clusters of keywords or phrases obtained by the Fruchterman Reingold method
(with K-core equal to 8)
Согласно приведенным визуальным представлениям выделяются следующие кластеры. Первый кластер объединяет ключевые слова и словосочетания вокруг ключевого словосочетания «безэкипажное судно», сюда входят понятия, связанные с современными информационными технологиями, использующимися для управления безэкипажным судном. Второй кластер включает в себя ключевые слова и словосочетания, связанные с автономным судоходством («автономное судно», «автономное судовождение», «автономное судоходство», «автономность»), сюда входят публикации, которые освещают вопросы, связанные с обеспечением безопасности движения автономных судов. Третий кластер содержит такие ключевые слова и словосочетания, как «безэкипажное судовождение», «безэкипажное судоходство», а также «А-навига-ция» и «Е-навигация», соответствующие научные публикации направлены на описание различных программных средств обеспечения цифровой навигации. Четвертый кластер в качестве основного ядра содержит понятие безэкипажного катера, в этом кластере активно используются термины, связанные с применением систем искусственного интеллекта для управления безэкипажными катерами («нейронные сети», «нечеткая логика»). Пятый кластер развернулся вокруг ключевого словосочетания «МАНС», в этот кластер вошли такие ключевые слова и словосочетания, которые описывают нормативно-правовые особенности, определяющие возможности создания, тестирования и эксплуатации морских автономных надводных объектов («правовое регулирование», «международное морское право», «международная морская организация», «морское право»).
Данные по полученным неориентированным графам, соответствующим кластерам ключевых слов и словосочетаний научных публикаций по морскому автономному надводному судоходству, сведены в табл. 2. Диаметр графа (параметр, определяющий число вершин, которые необходимо миновать, чтобы пройти кратчайшим путем между двумя наиболее удаленными вершинами), равный трем, а также значения среднего коэффициента кластеризации (характеризующегося действительным числом, которое принимает нулевое значение, когда вообще отсутствуют кластеры, и единицей, когда граф целиком состоит из не связанных между собой вершин), располагающегося в отрезке [0,5; 0,6], позволяет сделать вывод о том, что наилучшими значениями параметра K-core, использующегося для построения кластеров неориентированных графов, являются параметры с 6 по 8.
Таблица 2
Table 2
Таблица характеристик неориентированных графов, полученных методом ForceAtlas 2 при различных K-core
The undirected graphs characteristics obtained by the ForceAtlas 2 method with different K-cores
|
№ характеристики |
Разновидность характеристики |
K-core = 1 |
K-core = 2 |
K-core = 3 |
K-core = 4 |
K-core = 5 |
K-core = 6 |
K-core = 7 |
K-core = 8 |
|
1 |
Средняя степень |
4,281 |
6,836 |
9,575 |
11,284 |
12,63 |
13,743 |
14,532 |
15,038 |
|
2 |
Cредняя взвешенная степень |
5,6 |
9,489 |
14,319 |
17,686 |
20,767 |
23,339 |
26,38 |
30,615 |
|
3 |
Диаметр графа |
6 |
4 |
4 |
4 |
4 |
3 |
3 |
3 |
|
4 |
Плотность графа |
0,003 |
0,012 |
0,032 |
0,056 |
0,087 |
0,127 |
0,186 |
0,295 |
|
5 |
Модулярность |
0,484 |
0,401 |
0,378 |
0,348 |
0,291 |
0,289 |
0,237 |
0,225 |
|
6 |
Средний коэффициент кластеризации |
0,782 |
0,8 |
0,703 |
0,629 |
0,552 |
0,526 |
0,546 |
0,578 |
|
7 |
Средняя длина пути |
3,067 |
2,625 |
2,354 |
2,232 |
2,152 |
2,004 |
1,877 |
1,715 |
Заключение
Таким образом, осуществлен поиск научных публикаций, относящихся к вопросам, связанным с разработкой и управлением автономными или безэкипажными морскими судами. Проведен интеллектуальный анализ полученных данных, результаты визуализированы в виде неориентированных графов, отображающих кластеры ключевых слов или словосочетаний, наиболее часто встречающихся совместно в научных публикациях, представляющих результаты по созданию, управлению, нормативно-правовому обеспечению автономного и безэкипажного судоходства.
Подобный подход к обработке публикаций позволяет наглядно и доступно визуализировать и кластеризовать взаимосвязи в научных публикациях, отмечая основные тенденции, и может оказаться полезным студентам, аспирантам и научным работникам для выявления основополагающих терминов и понятий, имеющих важнейшее значение в публикациях по выбранной тематике.
1. Liu Mingwei, Zhao Chengyuan, Peng Xin, Yu Siming, Wang Haofen, Sha Chaofeng. Task-Oriented ML/DL Library Recommendation based on a Knowledge Graph. IEEE Transactions on Software Engineering. 2023. P. 1–16.
2. Huang Kun, Li Xiaoming, Liu Fangyuan, Yang Xiaoping, Yu Wei. ML-GAT: A Multilevel Graph Attention Model for Stock Prediction // IEEE Access. 2022. V. 10. P. 86408–86422.
3. Singh Inder, Ghorbel Enjie, Oyedotun Oyebade, Aouada Djamila. Multi Label Image Classification using Adaptive Graph Convolutional Networks (ML-AGCN). 2022. URL: https://orbilu.uni.lu/handle/10993/51776 (дата обращения: 01.03.2024).
4. Zhansultan A., Sanzhar A., Trigo P. Parallel implementation of force algorithms for graph visualization // Journal of Theoretical and Applied Information Technology. 2021. V. 99. N. 2. P. 503–515.
5. Ammar Kh. A., Kheir A. M. S., Manikas I. Agricultural big data and methods and models for food security analysis – a mini-review // PeerJ. 2022. V. 10. P. e13674. DOI:https://doi.org/10.7717/peerj.13674.
6. Marqués-Sánchez P., Pinto-Carral A., Fernández-Villa T., Vázquez-Casares A., Liébana-Presa C., Benítez-Andrades J. A. Identification of cohesive subgroups in a university hall of residence during the COVID-19 pandemic using a social network analysis approach // Scientific Reports. 2021. V. 11. N. 1. P. 1–10. DOI:https://doi.org/10.1038/s41598-021-01390-4.
7. Woolley T., Stubbs Ja. R., Sprague E., Suiter A. M., Sarli C. C., Strandenes G., Spinella P. C. The publication impact of the first 100 THOR Network publications by bibliometric and social network analyses // Transfusion. 2022. V. 62. P. 1–11. DOI:https://doi.org/10.1111/trf.16956.
8. Bykov I. A., Martyanov D. S. Studying political communities in vk.com with network analysis // Galactica Media: Journal of Media Studies. 2021. V. 3. N. 1. P. 64–78. DOI:https://doi.org/10.46539/gmd.v3i1.144.
9. Вронский К. А., Шеленок Е. А. Программный модуль построения социальных графов сообществ сети «Вконтакте» // Вестн. Тихоокеан. гос. ун-та. 2021. № 2 (61). С. 71–80.
10. Улизко М. С., Артамонов А. А., Тукумбетова Р. Р., Антонов Е. В., Васильев М. И. Критические пути распространения информации в сетях // Науч. визуализация. 2022. Т. 14. № 2. С. 98–107. DOI:https://doi.org/10.26583/sv.14.2.09.
11. Павлов К. В. Виртуальные реконструкции объектов историко-культурного наследия как научное направление (1996–2020): структура научной коммуникации в контексте анализа цитирований // Истор. информатика. 2021. № 3 (37). С. 162–178. DOI:https://doi.org/10.7256/2585-7797.2021.3.36513.
12. Goldmeier J. Data Smart: Using Data Science to Transform Information into Insight. John Wiley and Sons, 2023. 448 p.
13. Bastian M., Heymann S., Jacomy M. Gephi: An Open Source Software for Exploring and Manipulating Networks. International AAAI Conference on Weblogs and Social Media, North America, 2009. URL: http://www.aaai.org/ocs/index.php/ICWSM/09/paper/view/154 (дата обращения: 05.02.2023).
