










Россия
Россия
Россия
Россия
В настоящее время российские компании, производящие программное и аппаратное обеспечение для теле- и радиовещания, могут почерпнуть информацию о мировых новинках и тенденциях в сфере своей деятельности в профильной научно-популярной литературе (журналах, дайджестах), на официальных сайтах зарубежных конкурентов, а также на выставках и презентациях. Однако именно возможность всесторонне проанализировать новинки зарубежных разработчиков, запатентованных в мировых патентных базах, даст российским компаниям конкурентные преимущества при формировании стратегических планов развития. Предлагается сформировать патентный ландшафт на основе данных мирового патентного массива (на английском языке) в области теле- и радиовещания, проанализировать патентные тренды и спрогнозировать развитие технологий в данной области. Новизна разработанного метода прогнозирования развития технологий заключается в кооперации методов кластеризации патентов USPTO (США) на основе международной патентной классификации и прогнозирования технологических трендов посредством сформированных временных рядов. Разработанный метод программно реализован на языке Python, при распараллеливании процесса парсинга патентов использована библиотека Multiprocessing, для анализа данных и проведения процесса прогнозирования – Statsmodels, для визуализации данных – Matplotlib. Для организации хранения информации была выбрана система управления базами данных MySQL. Обработано 28 591 патентов, проведено тестирование процесса прогнозирования развития теле- и радиотехнологий на основе построенных временных рядов на интервале 2015–2020 гг.
теле- и радиовещание, парсинг, патент, построение временных рядов, прогнозирование развития технологий
Введение
В настоящее время российские компании, производящие программное и аппаратное обеспечение для теле- и радиовещания, могут почерпнуть знания
о мировых новинках и тенденциях в сфере своей деятельности в профильной научно-популярной литературе (журналах, дайджестах), а также на основе сведений официальных сайтов зарубежных конкурентов, информации с выставок и презентаций.
Возможность всесторонне проанализировать разработки зарубежных конкурентов может дать российским компаниям конкурентные преимущества при формировании стратегических планов развития. В связи с этим актуальной проблемой является автоматизация сбора, прогнозирования и визуализации статистических и прогнозных данных о развитии технологий в области теле- и радиовещания.
Новизна разрабатываемого метода прогнозирования развития технологий на основе данных мирового патентного массива (на английском языке) в области теле- и радиовещания заключается в кооперации методов кластеризации патентов USPTO (США) при помощи международной патентной классификации
и прогнозирования технологических трендов посредством сформированных временных рядов.
К разрабатываемому методу можно предъявить следующие требования:
– парсинг патентных данных (извлечение текстовых данных из полей патента «Описание», «Формула изобретения» и метаданных (классы международной патентной классификации (МПК, IPC) [1], списки цитирований, принадлежность к патентному семейству (Patent Family) и т. д.) осуществляется с сайта Google Patents, причем из классов Международной патентной классификации, соответствующих области теле- и радиовещания;
– построение временных рядов [2] на основе патентных данных для прогнозирования развития технологий в области теле- и радиовещания осуществляется на основе метода Autoreg Ressive Integrated Moving Average (ARIMA) [3].
Материалы и методы
Существующих решений с аналогичным функционалом в области теле- и радиовещания не было найдено, по этой причине было решено проанализировать следующие программные продукты в области аналитики патентных данных: PatSeer [4], Acclaim IP [5], Patent INSIGHT Pro [6], Thomson Reuters [7].
Сравнение существующих решений осуществлялось по следующим критериям:
– актуальность данных;
– коллаборация с другими исследователями;
– просмотр полной информации о патенте;
– наличие патентов разных стран мира;
– визуализация аналитики;
– прогнозирование.
Результаты проведенного сравнительного анализа вышеописанных решений представлены в таблице.
Сравнительный анализ решений
Comparative analysis of solutions
|
Решение Критерий |
PatSeer |
Acclaim IP |
Patent INSIGHT Pro |
Thomson Reuters |
|
Актуальность данных |
+ |
+ |
+ |
+ |
|
Просмотр полной информации о патенте |
– |
+ |
– |
– |
|
Наличие патентов разных стран мира |
+ |
– |
+ |
+ |
|
Визуализация аналитики |
+ |
+ |
+ |
+ |
|
Прогнозирование данных |
– |
– |
– |
– |
Исходя из результатов проведенного анализа, а также из поставленных функциональных требований, было решено разработать метод прогнозирования развития технологий в области теле- и радиовещания и реализовать в виде программного обеспечения (ПО).
Диаграмма потоков данных разрабатываемого метода представлена на рис. 1.
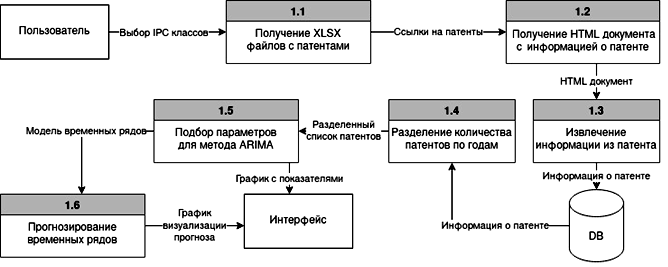
Рис. 1. Диаграмма потоков данных
Fig. 1. Data flow graph
Разрабатываемый метод включает в себя парсинг патентного массива, прогнозирование и визуализацию статистических и прогнозных данных.
Алгоритм парсинга страниц сайта Google Patents содержит следующие шаги (рис. 2):
– выбор классов IPC;
– создание директорий для хранения файлов;
– парсинг патента;
– определение общего количества обработанных патентов;
– запись распарсенной информации в БД.
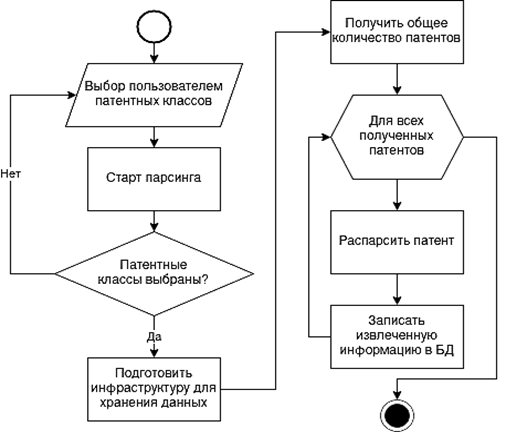
Рис. 2. Общий алгоритм парсинга
Fig. 2. General parsing algorithm
Алгоритм сбора патентной информации содержит в себе следующие шаги (рис. 3):
– получение ссылок из XLSX-документов с патентами;
– загрузка страницы при помощи бота;
– запись HTML-кода [8] в файл;
– парсинг информации из HTML;
– проверка наличия патента в БД;
– получение ссылки на сайт с дополнительной информацией о патенте;
– парсинг дополнительных данных с сайта;
– запись данных в словарь.
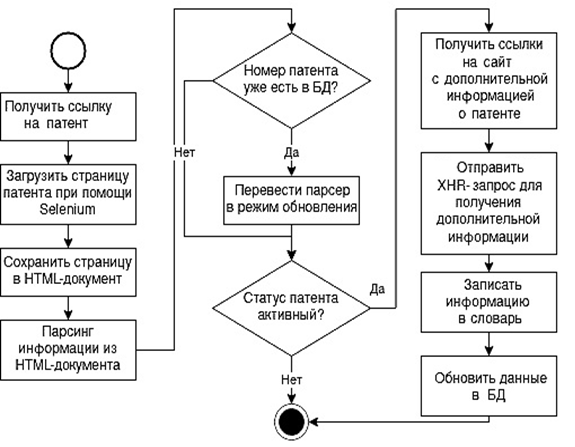
Рис. 3. Алгоритм сбора и обновления патентной информации
Fig. 3. Algorithm for collecting and updating patent information
Алгоритм построения временных рядов на основе патентных данных и прогнозирования развития технологий на основе метода ARIMA приведен на рис. 4 и содержит следующие шаги:
– выбор патентного класса (на основе этого выбора будут определены количество патентов и их идентификационные номера);
– поиск патентов по их идентификационным номерам в БД;
– разбиение патентных данных по временным отрезкам на основе информации о дате выдачи патента;
– прогнозирование при помощи модели ARIMA;
– визуализация статистических и прогнозных данных.
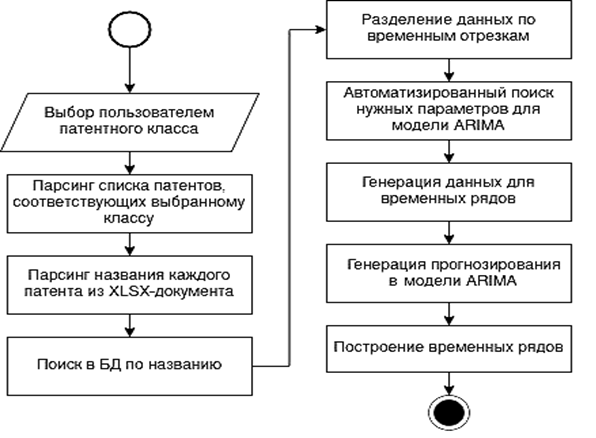
Рис. 4. Алгоритм прогнозирования на основе временных рядов
Fig. 4. Time series forecasting algorithm
Диаграмма вариантов использования проекти
руемого ПО представлена на рис. 5.

Рис. 5. Диаграмма вариантов использования проектируемого ПО
Fig. 5. Use case diagram of the developed software
Актор – это пользователь, которому доступны основные функции:
– выбор необходимых IPC-классов;
– парсинг патентов;
– просмотр БД;
– прогнозирование развития технологии.
Архитектура проектируемого программного обеспечения представлена на рис. 6.
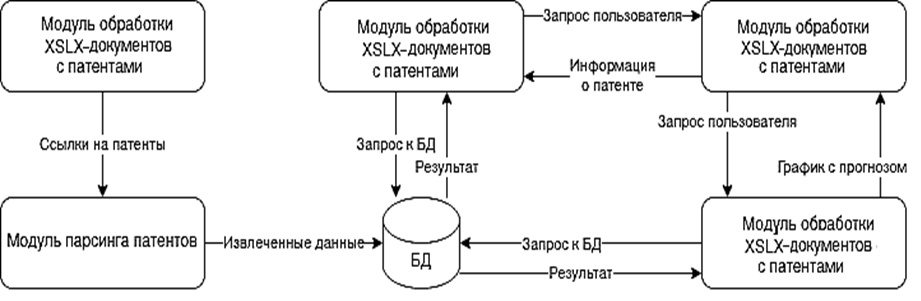
Рис. 6. Архитектура разрабатываемого ПО
Fig. 6. Architecture of the developed software
В качестве языка программирования выбран Python [9], для реализации интерфейса – библиотека Tkinter [10]. Для сбора файлов с массивами патентов с GooglePatents задействована библиотека Request [11], благодаря которой можно выполнять XHR-запросы (XMLHttpRequest) [12] напрямую
к серверу, что поспособствовало увеличению скорости работы программы в части сбора информации. Для извлечения данных из файлов с патентами
использованы библиотеки BeautifulSoup [13] и Selenium [14] (программная библиотека для управления браузерами посредством созданного бота, позволяющего прогрузить html-страницу). Поскольку анализируется мировой массив патентов из GooglePatents [15], то системе необходимо обрабатывать огромное количество данных, следовательно, актуальным является распараллеливание процесса парсинга. Для этого использована библиотека Multiprocessing [16], которая позволяет распараллелить вычисления для ускорения парсинга. Для анализа данных и прогнозирования была использована библиотека Statsmodels [17], для визуализации прогнозных и статистических данных использована библиотека Matplotlib [18].
Также в качестве системы управления базой данных использована MySql [19, 20]. Схема спроектированной базы данных представлена на рис. 7.
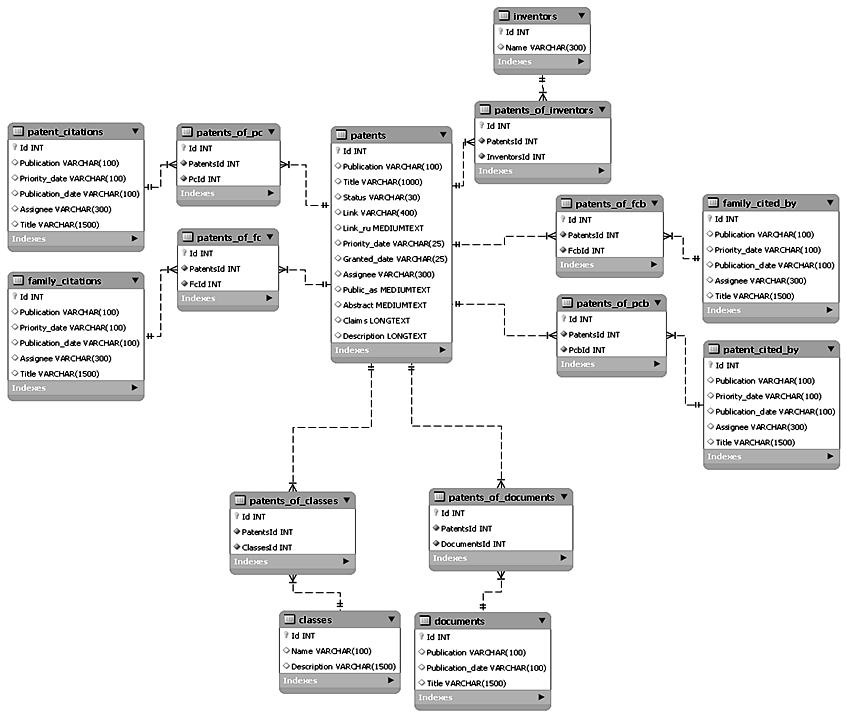
Рис. 7. Структура БД
Fig. 7. Structure of the database
Таблица «patents» – центральная, содержит основную патентную информацию, включая текстовые поля «Abstract», «Description», «Claims»; таблица «inventors» – информацию о патентных изобретателях; таблица «classes» – патентные классы, к которым относится патент; таблица «documents» хранит информацию о схожих патентах согласно алгоритмам GooglePatents; таблицы «patent_citations» и «family_citations» содержат списки цитирований для патента (патентного семейства); таблицы «patent_cited_by» и «family_cited_by» хранят информацию о патентах, которые цитировали данный патент (патентное семейство).
Разработанное ПО апробировано на патентном массиве Google Patents. На вход модуля парсинга подаются xlsx-файлы, содержащие ссылки на патенты Google Patents, зарегистрированные в промежутке времени между 2015 и 2020 гг. (рис. 8), html-файлы с патентной информацией, а также интересующий класс IPC.
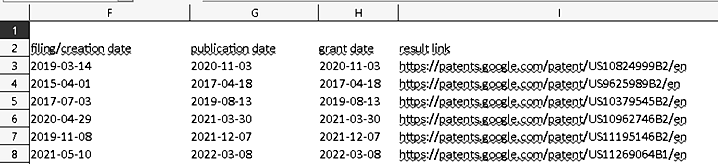
Рис. 8. Пример файла со ссылками
Fig. 8. Example of a file with links
Файлы собираются с сайта Google Patents автоматически, при помощи XHR-запросов, в результате выполнения которых извлекаются ссылки на патенты. Ссылки добавляются в массив и передаются в пул процессов для ускорения процесса парсинга. Создается директория html_for_process, в которой формируются html-файлы для каждого процесса (рис. 9).
Рис. 9. HTML-документы для процессов
Fig. 9. HTML documents for processes
В каждом процессе сайт загружается по ссылке через бота, созданного при помощи библиотеки Selenium, и весь html-код записывается в файл, соответствующий процессу, информация о патенте сохраняется в словарь (рис. 10).
Собранные данные добавляются в очередь, после чего записываются в БД.
Для активизации парсинга требуется выбрать классы IPC, которые требуются пользователю.
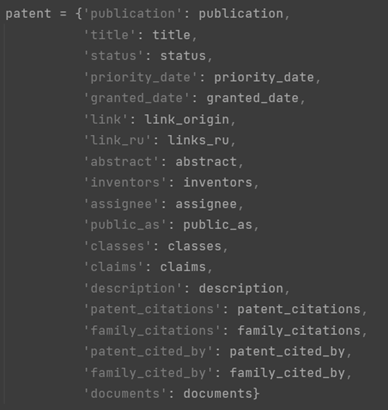
Рис. 10. Пример словаря с информацией о патенте
Fig. 10. Example of a dictionarywith information about a patent
В режиме просмотра информации из БД на странице отображается навигационная панель, поле поиска, список с найденными патентами, поля для отображения информации из БД (название, идентификационный номер, ссылки, дата подачи, дата одобрения, статус, изобретатели, патентообладатели и т. д.) (рис. 11).
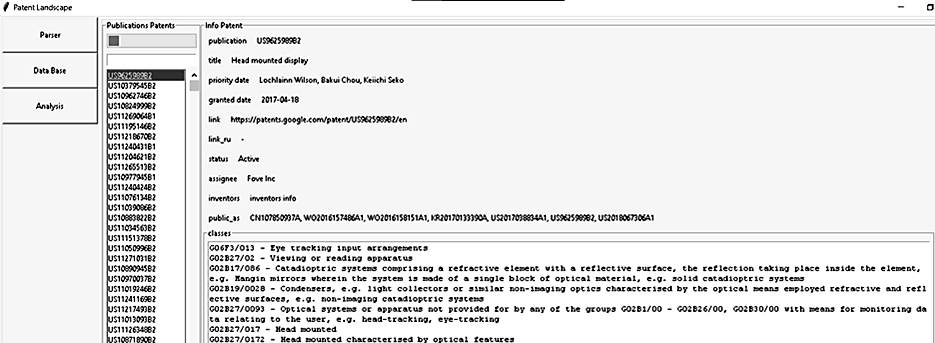
Рис. 11. Просмотр патентной информации
Fig. 11. Viewing patent information
При запуске процесса прогнозирования развития технологий указывается конкретный класс IPC, который выбирает пользователь. На рис. 12 представлено сравнение результатов прогнозирования (серая кривая) и реальная информация временных рядов (количество патентов, соответствующих указанному патентному классу, в данном временном периоде) (черная кривая).
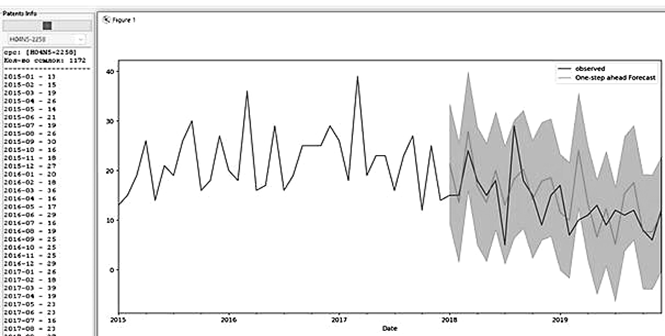
Рис. 12. График с прогнозированием
Fig. 12. Prediction diagram
Общая тенденция к плавному затуханию патентования технологии, соответствующей классу H04N5/2258 «Камеры, использующие два или более датчика изображения, например, CMOS-сенсор для видео и CCD-матрицу для неподвижного изображения», прослеживается как на реальных, так и на прогнозируемых данных.
В процессе работы распарсены патенты из Google Patents для класса IPC H04N «Передача изображений, например, телевидение» в количестве
28 591 патентов и записаны в спроектированную БД.
Возможные направления совершенствования системы:
– оптимизация системы парсинга, полный переход на XHR-запросы к серверу;
– улучшение автоматического подбора параметров для модели ARIMA или использование других методов прогнозирования;
– установка разработанного программного обеспечения на кластерную многонодовую систему для ускорения обработки патентных данных.
Область применения разработанного метода – анализ мирового патентного массива [21–23], содержащегося в Google Patents, для прогнозирования и визуализации статистических и прогнозных данных о развитии технологий в области теле- и радиовещания.
Заключение
Разработан метод прогнозирования развития технологий на примере теле- и радиовещания, спроектировано, программно реализовано и протестировано программное обеспечение, реализующее разработанный метод. Было проведено тестирование процесса прогнозирования развития теле- и радиотехнологий на основе построенных временных рядов на интервале 2015–2020 гг.
Новизна метода прогнозирования развития технологий заключается в кооперации методов кластеризации патентов USPTO (США) на основе международной патентной классификации и прогнозирования технологических трендов посредством сформированных временных рядов.
Практическая значимость исследования заключается в разработанном программном обеспечении прогнозирования развития технологий в области теле- и радиовещания. Данная программная разработка вышла в финал отборочного этапа IV Всероссийского научно-технического конкурса разработок и научно-практических решений в области кинопроизводства, телерадиовещания и телекоммуникаций «Первый шаг».
1. International Patent Classification (IPC) // WIPO. URL: https://www.wipo.int/classifications/ipc/en/ (дата обращения: 05.03.2023).
2. Открытый курс машинного обучения. Тема 9. Анализ временных рядов с помощью Python // Хабр. URL: https://habr.com/ru/company/ods/blog/327242/ (дата обращения: 05.03.2023).
3. Прогнозирование временных рядов с помощью ARIMA в Python 3 // 8host. URL: https://8host-com.turbopages.org/8host.com/s/blog/prognozirovanie-vremennyx-ryadov-s-pomoshhyu-arima-v-python-3/ (дата обращения: 05.03.2023).
4. Patseer. URL: https://patseer.com/ (дата обращения: 05.03.2023).
5. Speed, Ease-of-use, and Global Patent Data // Ac-claimip. URL: https://www.acclaimip.com/ (дата обращения: 05.03.2023).
6. Patent iNSIGHT Pro. URL: https://www.patentinsightpro.com/ (дата обращения: 05.03.2023).
7. Imagine a new era with generative AI // Thomson Reuters. URL: https://www.thomsonreuters.com/en.html (дата обращения: 05.03.2023).
8. Справочник по HTML. URL: http://htmlbook.ru/html (дата обращения: 05.03.2023).
9. Python. URL: https://www.python.org/ (дата обращения: 05.03.2023).
10. Tkinter - Python interface to Tcl/Tk // Python. URL: https://docs.python.org/3/library/tkinter.html (дата обращения: 05.03.2023).
11. Документация по библиотеке Python Requests // Digitology.tech. URL: https://digitology.tech/docs/requests/index.html (дата обращения: 05.03.2023).
12. XMLHttpRequest // М mdn web docs. URL: https://developer.mozilla.org/ru/docs/Web/API/XMLHttpRequest (дата обращения: 05.03.2023).
13. Документация Beautiful Soup. URL: https://www.crummy.com/software/BeautifulSoup/bs4/doc.ru/bs4ru.html (дата обращения: 05.03.2023).
14. Selenium для Python. Глава 1. Установка // Хабр. URL: https://habr.com/ru/post/248559/ (дата обращения: 05.03.2023).
15. Google Patents // Google. URL: https://patents.google.com (дата обращения: 05.03.2023).
16. Multiprocessing - Process-based parallelism // Python. URL: https://docs.python.org/3/library/multiprocessing.html (дата обращения: 05.03.2023).
17. Statsmodels 0.14.0 // Statsmodels. URL: https://www.statsmodels.org/stable/index.html (дата обра-щения: 05.03.2023).
18. Matplotlib: Visualization with Python // Matplotlib. URL: https://matplotlib.org/ (дата обращения: 05.03.2023).
19. MySQL Documentation // MySQL. URL: https://dev.mysql.com/doc/ (дата обращения: 05.03.2023).
20. Cursor Objects // PyMySQL. URL: https://pymysql.readthedocs.io/en/latest/modules/cursors.html (дата обращения: 05.03.2023).
21. Korobkin D., Saveliev M., Vereschak G., Fomenkov S. The Building a Patent Landscape for Technological Forecasting Tasks // Advances in Automation IV: Conference paper. 2023. V. 986. P. 314-324. DOI: https://doi.org/10.1007/978-3-031-22311-2_31.
22. Kolesnikova V., Korobkin D., Fomenkov S., Rayushkin E., Glushkin V. The Analysis of Technology Development Trends Based on the Network Semantic Structure “Subject-Action-Object” // Studies in Systems, Decision and Control. 2022. V. 417. P. 43-53. DOI: https://doi.org/10.1007/978-3-030-95116-0_4.
23. Manukyan A., Korobkin D., Fomenkov S., Kolesnikov S. Semantic patent analysis with Amazon Web Services // Journal of Physics: Conference Seriesthis link is disabled. 2021. V. 2060 (1). P. 012025. DOI:https://doi.org/10.1088/1742-6596/2060/1/012025.
