










Краснодар, Краснодарский край, Россия
В настоящее время актуальным направлением исследований является разработка современных решений для анализа паттернов поведения пользователей, которые в профессиональной среде известны как системы аналитики поведения пользователей и сущностей. Предлагается рассмотреть возможность построения таких систем с использованием методов машинного обучения. Это обусловлено увеличением источников и объема данных о пользователе, в результате чего ручной анализ трудозатратен, а классические методы на основе статистики или правил не всегда обеспечивают требуемое качество детекции аномалий. Целью работы является построение эффективного алгоритма машинного обучения для задачи обнаружения аномалий в данных. Предложен алгоритм обнаружения аномального поведения пользователей автоматизированных систем, а также оптимизационный алгоритм на основе искусственной иммунной системы для выбора наилучших гиперпараметров алгоритма. Алгоритм обнаружения аномалий основан на классификации поведения пользователей в системе на основе их действий с использованием модели генеративно-состязательной сети. Предлагаемый алгоритм позволяет генерировать дополнительные выборки с распределением генеральной совокупности в целях сокращения времени внедрения и классифицировать пользователей на основе сформированных паттернов нормального поведения. Отличительная особенность алгоритма заключается в его способности адаптироваться к реальной системе, обучаясь на пользовательских данных и сохраняя при этом заданную точность классификации благодаря автоматическому подбору оптимальных гиперпараметров. Научная новизна предлагаемого алгоритма заключается в добавлении процедуры кластеризации в процесс аннотирования данных перед обучением модели машинного обучения, а также адаптации генеративно-состязательной сети для задачи обнаружения аномалий в данных путем изменения алгоритма обучения. Предлагаемый подход позволит с высокой точностью выявлять отклонения от нормального поведения пользователей в автоматизированном режиме и приближенно к реальному времени, что сократит время обработки событий информационной безопасности.
машинное обучение, обнаружение аномалий, поведенческий анализ, безопасность информации
Введение
В современных условиях, когда объемы данных продолжают расти с экспоненциальной скоростью, а количество пользователей информационных систем увеличивается, проблема контроля пользователей и их информационных потоков становится более актуальной, чем когда-либо. В качестве систем, направленных на решение поставленной проблемы, выступает класс программных решений поведенческой аналитики пользователей, в профессиональной сфере известных как User and Entity Behavior Analytics (UEBA), – системы анализа поведения пользователей и сущностей. Решения данного класса являются ключевым инструментом для выявления и предотвращения потенциальных угроз в автоматизированных системах за счет обнаружения отклонений в действиях пользователей. Вопрос обнаружения аномального поведения пользователей на основе анализа действий в системе актуален уже не одно десятилетие, меняя вектор своего развития, т. к. постоянно появляются новые технологии и меняются существующие. Так, одним из активно развивающихся направлений является использование в UEBA-системах алгоритмов интеллектуальной обработки данных и машинного обучения [1].
Существующие работы по теме исследования предлагают различные подходы к реализации выявления аномалий в действиях пользователя, но при этом имеют ряд существенных недостатков. Так, в отдельных работах [2–4] предлагается использовать статистические и линейные алгоритмы, что является эффективным только в случаях, когда анализ проводится на небольшой выборке и ограниченным набором признакового пространства. В то же время современные условия функционирования автоматизированных систем диктуют обратное: множество разнородных источников данных и большое количество событий, которые требуется анализировать в совокупности. Другая часть работ [5–8] учитывает особенности функционирования автоматизированных систем, и авторы предлагают использовать модели машинного обучения для обнаружения аномалий, но при этом по-прежнему анализ производится только на ограниченном признаковом пространстве и рассматривает поведение пользователя само по себе, без учета сущностей работы системы.
Алгоритм обнаружения аномального поведения пользователей
На основе проведенного анализа существующих подходов в исследовании предлагается использовать более современную генеративно-состязательную модель машинного обучения (GANs), структурно состоящую из двух нейронных сетей (генератора и дискриминатора).
Важно отметить, что используемый в работе метод генеративно-состязательной сети относится к классу методов глубокого машинного обучения, основанных на нейронных сетях. В отличие от традиционных алгоритмов машинного обучения (например, SVM, Random Forest, Isolation Forest), которые в основном применяются к строго структурированным данным, нейронные сети и, в частности, генеративно-состязательные сети обладают способностью обрабатывать сложные, частично неструктурированные данные, такие как поведенческие признаки пользователей, журналы действий, последовательности событий и др. Это особенно важно в задачах анализа поведения, где высокая изменчивость и сложная семантика данных ограничивают применение классических подходов. Генеративно-состязательные сети позволяют моделировать латентные закономерности в поведенческих паттернах и выявлять отклонения, выходящие за пределы обученного распределения. Таким образом, использование именно предлагаемого метода, а не более простых моделей обусловлено необходимостью гибкой обработки разнообразных и потенциально неструктурированных поведенческих признаков в рамках автоматизированных систем.
В задачи генератора входит создание новых данных с распределением генеральной совокупности, что позволит сократить время внедрения предлагаемого решения до 1 месяца, в то время как существующие UEBA-системы требуют для сбора данных и обучения от 3 до 6 месяцев непрерывного функционирования. Дискриминаторную модель предлагается использовать в режиме бинарного классификатора, что позволит отделять нормальное поведение пользователя от аномалий. В ходе состязательного обучения генератора и дискриминатора, где генератор будет стремиться создавать максимально правдоподобные примеры поведения пользователя, а дискриминатор находить отличия между исходной и генерируемой совокупностью данных, мы будем стремиться минимизировать ошибки работы дискриминатора. Данный подход отличается от эталонной модели генеративно- состязательных сетей, где минимизируют ошибки генератора исходя из первоначальной задачи этого класса моделей. Также предлагается добавить кластеризацию данных перед обучением генеративно-состязательной сети, это позволит дискриминатору точнее определять аномалии по классу пользователей и заведомо уберет выбросы (пользователей, не похожих на свою группу). Данный способ также отличается от предлагаемых решений UEBA-систем, анализ которых приведен далее, где используются данные из единого пространства пользователей для формирования классов. При таком подходе, в случае наличия в группе легитимного пользователя с повышенными привилегиями, система будет его определять как аномалию по классу, что придется фильтровать вручную. Предлагаемый же подход позволяет автоматизировать данный процесс в целях сокращения времени обнаружения аномальных событий информационной безопасности. Схема работы предлагаемого алгоритма представлена на рис. 1. Обучение модели генеративно-состязательной сети проводилось на выборочной совокупности действий 800 пользователей, собираемых в течение месяца. Признаковое пространство включает несколько основных блоков данных о поведении пользователей:
– пользователь (ID пользователя);
– журнал удаленного доступа (данные о подключении к службе удаленных рабочих столов);
– мониторинг процессов (данные о запускаемых процессах и их количество);
– мониторинг доступа к USB (данные о действиях пользователя с отчуждаемыми машинными носителями информации);
– сетевая активность (данные о количестве полученного и отправленного трафика);
– локальные действия пользователей (биометрические данные пользователя);
– системные метрики (данные о загруженности ресурсов автоматизированной системы);
– журнал аутентификации (данные о процессе аутентификации пользователя);
– изменение файловой системы (действия с файловой системой).
Перед подачей данных для обучения производится их предварительная обработка, включающая кодирование категориальных признаков, нормализацию значений, обработку выбросов и пропущенных значений. Методом One-Hot Encoding каждый категориальный тип данных представляется как отдельный бинарный столбец. Нормализация данных осуществляется логарифмическим преобразованием (натуральный для экспоненциальных значений признаков и десятичный для признаков разного порядка). Применение данного метода нормализации обусловлено широким диапазоном значений и требованием к сохранению информативности каждого признака. Подробное описание формирования признакового пространства для задачи обнаружения аномального поведения пользователей представлено в статье [9], где рассмотрены все основные этапы предварительной обработки и обоснование применяемых методов.
Обучение генеративно-состязательной сети происходит с использованием иммунного алгоритма оптимизации, эффективность которого уже была доказана [10, 11] в сравнении с полным перебором или случайным поиском. Алгоритм параметрической оптимизации гиперпараметров модели машинного обучения на основе алгоритма искусственной иммунной системы реализован в виде программы для ЭВМ [12], блок-схема которой представлена на рис. 2. Блок 3 определяет научную новизну предлагаемого алгоритма, которая заключается в добавлении весового коэффициента значимости в процесс мутации.

Рис. 1. Схема работы алгоритма обнаружения аномалий в данных
Fig. 1. Scheme of the operation of the data anomaly detection algorithm

Рис. 2. Блок-схема программы параметрической оптимизации
Fig. 2. Block diagram of the parametric optimization program
Входными данными алгоритма является набор гиперпараметров, к которым применяется иммунный алгоритм параметрической оптимизации. Выходными данными является матрица оптимальных гиперпараметров, которые передаются в предлагаемый алгоритм обнаружения на основе генеративно-состязательной нейронной сети.
Главной задачей процесса оптимизации является подбор наилучшего набора гиперпараметров H* из области допустимых значений Q, от которых напрямую зависит эффективность работы предлагаемого алгоритма:
![]()
Целевая функция зависит от трех ключевых параметров: результативности (Rez), оперативности (Oper) и ресурсоемкости (Res). В представленной постановке задача является многокритериальной и заключается в нахождении Парето-оптимальных
решений. Результирующее значение эффективности E получается путем мультипликативной свертки параметров и добавлением весовых коэффициентов значимости  i каждого параметра, значение которых определяется экспертным методом:
i каждого параметра, значение которых определяется экспертным методом:
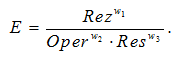
В качестве составляющих для расчета результативности предлагаемого алгоритма выступают метрики оценки качества моделей машинного обучения, выбранные в соответствии с национальным стандартом [13], а именно показатель F-меры и площади под кривой ROC (roc-auc). Результаты расчета комплексного показателя результативности с использованием стандартной модели иммунного алгоритма, представленные на рис. 3, показывают низкую скорость сходимости показателей при переходе от поколения к поколению.

Рис. 3. Распределение показателя результативности по поколениям
Fig. 3. Distribution of the performance indicator by generations
В целях устранения выявленного недостатка предлагается введение весовых коэффициентов wi значимости гиперпараметров в механизм мутации, данный коэффициент определяется на основе матрицы корреляции Пирсона и имеет прямо пропорциональную зависимость:
![]()
На каждом поколении формируется множество особей (наборов гиперпараметров) x, которые мутируют с определенным отклонением N. Область допустимых значений отклонения рассчитывается для каждой особи на основе функции аффинности aff, которая определяет качество модели по метрикам F-меры и roc-auc. Добавленный весовой коэффициент влияет на дисперсию мутации: чем выше вес гиперпараметра, тем меньше он мутирует. Результаты расчета комплексного показателя результативности с учетом весовых коэффициентов значимости представлены на рис. 4.
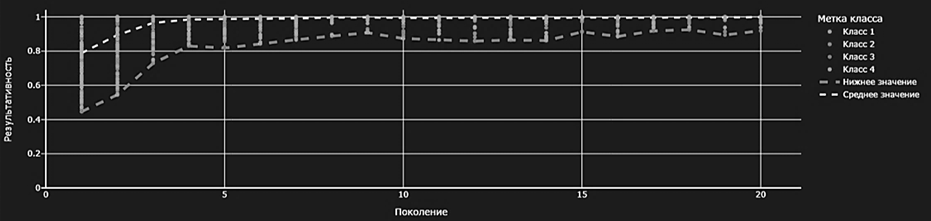
Рис. 4. Распределение показателя результативности по поколениям
Fig. 4. Distribution of the performance indicator by generations
Добавление весового коэффициента в процесс мутации позволяет сохранить значение наиболее значимого гиперпараметра в каждом поколении мутации. По результатам сравнения полученных значений комплексного показателя результативности было выявлено повышение скорости сходимости оптимизационного алгоритма на каждой итерации.
Оценка результативности предлагаемого алгоритма
В ходе исследования был проведен анализ существующих решений UEBA [14–17] и выделены основные алгоритмы, используемые в них. Часть решений использует предобученные модели машинного обучения, которые не отражают действительное положение дел в автоматизированных системах, а следовательно, анализируют лишь шаблонное поведение пользователей, которое заранее заложено в исходных данных для обучения. Другая же часть решений предлагает как статистические алгоритмы анализа, так и применение методов машинного обучения, таких как k-means (алгоритм k-средних), Isolation Forest (модель изоляционного леса), SVM (метод опорных векторов), DBSCAN (алгоритм кластеризации на основе плотности распределения), LOF-mod (алгоритм локальных выбросов).
На основе данных, полученных в ходе анализа, было проведено сравнение предлагаемого алгоритма с уже существующими методами на выборочной совокупности исходных данных. Результаты сравнения (рис. 5) показывают, что наилучшие результаты показали алгоритм локальных выбросов (LOF-mod) и предлагаемый в работе алгоритм генеративно-состязательной сети (GANs).

Рис. 5. Сравнительный анализ алгоритмов обнаружения аномалий в данных
Fig. 5. Comparative analysis of data anomaly detection algorithms
Таким образом, прирост в результативности предлагаемого алгоритма в сравнении с LOF-mod составляет 7,6 % по метрике F1-мера и 10 % по метрике ROC-AUC. Несмотря на близкие количественные показатели эффективности вышеупомянутых алгоритмов, предлагаемое в работе решение способно быстрее интегрироваться в систему ввиду отсутствия необходимости сбора большого набора данных.
Матрица ошибок для данной модели демонстрирует ее высокую точность и способность эффективно различать классы: из 10 000 событий модель правильно предсказала 4 815 положительных случаев (True Positives (TP)) и 4 875 отрицательных (True Negatives (TN)), при этом были допущены 125 ложноположительных ошибок (False Positives (FP), когда модель ошибочно отнесла отрицательные события к положительным, и 185 ложноотрицательных ошибок (False Negatives (FN)), когда положительные события были неверно классифицированы как отрицательные (табл.).
Матрица ошибок
Error matrix
|
Истинный класс |
Предсказано положительное |
Предсказано отрицательное |
|
Истинно положительное |
TP = 4 815 |
FN = 185 |
|
Истинно отрицательное |
FP = 125 |
TN = 4 875 |
Данные значения соответствуют усредненным значениям метрик модели: F1-мера – 0,9629, ROC-AUC – 0,9761 и PR-AUC – 0,9754, что подтверждает ее точность в идентификации классов и низкий уровень ошибок первого и второго рода.
Распределение событий информационной безопасности в ходе моделирования представлено на рис. 6.

Рис. 6. Распределение событий информационной безопасности
Fig. 6. Distribution of information security events
Гистограмма показывает накопление событий по 3 классам на каждом шаге процесса моделирования, а также долю угроз от общего числа событий, которые имитируются в модели. Каждый класс событий отражает группу пользователей, которые анализируются на аномальное поведение. Классы событий определяются путем предварительной кластеризации с использованием алгоритма k-средних. Под угрозами в данном случае понимаются аномальные события, которые отражают поведение внутреннего злоумышленника. На 20-й итерации происходит накопление минимального числа событий моделирования (10 000 событий), из которых 8 725 событий подвергаются анализу, а 1 275 попадают в блок сброса, т. к. не отнесены ни к одному классу событий. Минимальное число событий для моделирования рассчитывалось путем сравнения эмпирического и теоретического распределения с использованием критерия Пирсона.
Моделирование процесса обнаружения аномального поведения пользователей в автоматизированной системе производилось в среде имитационного моделирования CPNTools с использованием встроенного языка программирования CPN-ML. В модели учтены основные характеристики рассматриваемого объекта, такие как структура, распределение показателей функционирования и временные характеристики.
Заключение
Предлагаемый в работе алгоритм позволяет формировать паттерны нормального поведения пользователей и обнаруживать отклонения от него как по классу пользователей, так и индивидуально для каждого. В результате классификации для каждого пользователя формируется рейтинг безопасности, который увеличивается с ростом числа отклонений от нормального поведения. По достижении определенного порога рейтинга безопасности система в автоматическом режиме оповещает администратора безопасности о возможном инциденте, связанном с воздействием внутреннего злоумышленника.
Применение в алгоритме генеративно-состязательной сети дает возможность генерировать дополнительные синтетические данные поведения пользователя с исходным распределением, что сокращает время, необходимое для сбора и подготовки исходных данных. Как следствие, это уменьшает время, необходимое для внедрения такого решения в существующую систему защиты информации.
Процесс состязания двух нейронных сетей позволяет достичь высоких значений точности классификации с использованием дискриминатора благодаря адаптации модели к задаче обнаружения аномалий в данных, а внедрение иммунного алгоритма оптимизации способствует подбору оптимальных гиперпараметров модели машинного обучения для конкретной автоматизированной системы, учитывая особенности поведения всех пользователей.
1. Барабанов Д. А., Иванова Т. А., Гараев Р. А. Пер-спективы применения и сценарии использования анализа поведения пользователей в сфере информационной безопасности // Информационные технологии интеллектуальной поддержки принятия решений. 2019. Т. 1. С. 202–206.
2. Абрамова О. Ф. Визуализация паттерна поведения пользователя web-системы // Кибернетика и программирование. 2019. № 3. С. 43–52. DOI:https://doi.org/10.25136/2644-5522.2019.3.23017.
3. Беззатеев С. В., Елина Т. Н., Мыльников В. А., Лившиц И. И. Методика оценки рисков информацион-ных систем на основе анализа поведения пользователей и инцидентов информационной безопасности // Науч.-техн. вестн. информац. технологий, механики и оптики. 2021. Т. 21. № 4. С. 553–561. DOI:https://doi.org/10.17586/2226-1494-2021-21-4-553-561.
4. Ковалёв С. П., Калугина М. А. Комбинация алго-ритмов K-средних и DBSCAN при анализе поведения пользователей // Студенческий (электрон. науч. журн.). 2019. № 18 (62). С. 33–38. URL: https://sibac.info/journal/student/62/140295 (дата обращения: 15.05.2019).
5. Козин И. С. Метод обеспечения безопасности персональных данных при их обработке в информационной системе на основе анализа поведения пользователей // Информационно-управляющие системы. 2018. № 3. С. 69–78. DOI:https://doi.org/10.15217/1684-8853.2018.3.69.
6. Левковец Д. В., Алексеев И. В., Касаткин Д. П., Гурский С. М. Аутентификация пользователей на основе поведения на мобильных устройствах в различных контекстах использования // Вестн. науки. 2023. № 7 (64). С. 211–220.
7. Саенко И. Б., Котенко И. В., Аль-Барри М. Х. Применение искусственных нейронных сетей для выявления аномального поведения пользователей центров обработки данных // Вопр. кибербезопасности. 2022. № 2 (48). С. 87–94.
8. Машечкин И. В. Исследование и разработка инновационной технологии построения программных средств обеспечения компьютерной безопасности, основанных на использовании методов машинного обучения и математической статистики для анализа данных поведенческой биометрии пользователей при работе в рамках стандартного человеко-машинного интерфейса, для решения задач активной аутентификации и идентификации пользователей, обнаружения внутренних вторжений и предотвращения попытки хищения конфиденциальной информации: отчет о прикладных научных исследованиях. М.: Изд-во МГУ, 2016. 205 с.
9. Трунов Е. Е. Исследование источников данных о пользователе для формирования модели поведенческо-го анализа с целью предупреждения внутренних угроз нарушения безопасности информации // Охрана, без-опасность, связь. 2024. № 9-3. С. 111–118.
10. Шабанов А. А. Алгоритмы искусственной им-мунной системы в интервальных методах глобальной оптимизации: выпуск. квалификац. работа. Новоси-бирск: Изд-во НГУ, 2016. 51 с.
11. Лебедев Б. К., Лебедев О. Б., Лебедева Е. О., Нагабедян А. А. Гибридный роевой алгоритм глобаль-ной оптимизации в аффинном пространстве поиска // Программные продукты, системы и алгоритмы. 2019. Т. 1. С. 11–16.
12. Свидетельство о гос. регистрации программы для ЭВМ № 2025661274 Российская Федерация. Программа параметрической оптимизации гиперпараметров модели машинного обучения на основе алгоритма искусственной иммунной системы / Трунов Е. Е.; заявл. 27.04.2025: опубл. 05.05.2025.
13. ГОСТ Р 59898-2021. Оценка качества систем искусственного интеллекта. М.: Стандартинформ, 2021. 24 с.
14. IBM QRadar User Behavior Analytics. URL: https://www.ibm.com/ru-ru/marketplace/qradar-user-behavior-analytics (дата обращения: 10.10.2024).
15. Solar Dozor User Behavior Analytics. URL: https://rt-solar.ru/products/solar_dozor (дата обращения: 11.10.2024).
16. InfoWatch Prediction. URL: https://www.infowatch.ru/products/uba-sistema-prediction (дата обращения: 15.10.2024).
17. R-vision UEBA. URL: https://rvision.ru/products/ueba (дата обращения: 15.10.2024).
