












from 01.01.2022 until now
St. Petersburg, Russian Federation
When conducting recruiting procedures for a modern innovative company, the task of creating automated solutions designed to objectively determine the competencies of an employee is most urgent. There have been de-scribed the results of an analytical review of methods that allow identifying the competencies of specialists based on semantic studies of texts generated by them, followed by analysis of the applicability of such solutions to perform specific recruiting procedures. There is given a description of an approach to creating collections of texts characterizing the competencies of the applicant for the vacancy, which are classified according to the time of text generation (retrospective experience /current activity) and interaction with co-authors. There have been considered the examples of using different methods of Natural language processing based on the vector representation of texts for solving specific tasks related to the assessment of the competencies of specialists and the tools for semantic analysis of texts.
innovative enterprise, applicant for a vacancy, employee competencies, text processing, text collection, frequency of word occurrence
Введение
Происходящий в настоящее время повсеместный переход к технологиям Индустрии 4.0 в качестве основного конкурентного преимущества, обеспечивающего высокий темп инноваций, предполагает создание роботизированных производств во всех областях сервиса и технологий. Движущей силой инновационного развития по-прежнему остается когнитивная деятельность человека, основанная на полученных знаниях и опыте.
Особенно остро проблема подбора необходимых кадров возникает у так называемых инновационных предприятий, для которых удельная доля от реализации инновационного (т. е. не представленного ранее на рынке) продукта или услуги превышает
70 % от общего размера дохода [1]. Отличительными чертами таких компаний являются небольшой размер, работа в еще только формирующихся областях технологий или сервисов, высокая доля использования собственных ноу-хау в инновационных разработках и мультидисциплинарный характер работ.
Высокий уровень зарплат в таких компаниях приводит к тому, что на каждую объявляемую вакансию откликаются до нескольких сотен соискателей, из которых инновационные компании нанимают обычно не более 1 % претендентов [2]. В связи с этим выбор наилучшей кандидатуры становится достаточно сложной задачей, т. к. для проведения объективного и обоснованного выбора необходимого кандидата у компактного инновационного предприятия попросту не хватает временных ресурсов. При этом и со стороны инновационного предприятия часто оказывается достаточно трудно объективно определить и четко описать конкретный набор требований к кандидату.
На сегодняшний день было предпринято большое количество попыток создания программных средств, позволяющих автоматизировать процесс предварительной обработки комплекта подаваемых соискателем текстовых документов, основываясь на различных методах анализа. Подавляющая часть подобных разработок оказывается мало применима в случае инновационных предприятий, поскольку ориентирована на анализ ограниченных по номенклатуре текстов или основывается лишь на анализе формальных признаков образовательной подготовки или производственной квалификации соискателей, в связи с чем эти оценки не позволяют в полной мере отразить личные компетенции соискателей в развивающейся области технологий. Однако квалифицированный специалист в большинстве случаев является автором существенного количества текстовых материалов, отражающих его компетенции.
Поэтому актуальной является задача создания решений, предназначенных для определения компетенций работника на основе анализа семантики порождаемых им текстов.
В связи с этим целью настоящего исследования является проведение аналитического обзора возможных методов, позволяющих выявлять компетенции специалистов на основании изучения порожденных ими текстов, с последующим анализом применимости таких решений для выполнения конкретных процедур рекрутинга.
Подходы к формализации описания компетентностных качеств работника
Вопрос количественного учета и непосредственного использования знаний работников при построении систем управления бизнесом интересовал исследователей уже достаточно давно. С середины прошлого века разрабатывались модели, позволяющие связать роль опыта и знаний работников с темпами роста производства инновационной продукции, в состав которой тем или иным способом входит существенная часть формализованных знаний компании. Так, в работе [3] была описана модель экономического развития, основывающегося на знаниях
и инновациях. Позднее для учета производственных организационно-технических улучшений, создаваемых в процессе производства продукции, была предложена модель, описывающая инновационный прогресс в качестве основного способа повышения производительности труда, связанного с накоплением сотрудниками компании добавочного опыта, обусловленного выполнением ими своих непосредственных производственных обязанностей на рабочих местах [4].
Следующим шагом в уточнении описания влияния человеческого капитала на повышение эффективности бизнеса стала модель [5], учитывающая оценку сопоставимости влияния человеческого и материального капитала на процесс производства инноваций и предполагающая, что в капитале предприятия помимо материальных активов существенна роль интеллектуального вклада работников, в сущности представляющего собой овеществление человеческих знаний, существующих во всех промежуточных продуктах, использовавшихся для выпуска данного конечного продукта.
Однако основной прорыв в формальном описании производительных свойств работников предприятия стал возможен лишь в рамках создания концепции единых систем управления корпоративными знаниями, позволившей установить однозначную связь между корпоративными знаниями и их представлением в виде продукта информационных трансформаций, описываемым, в частности, в виде «модели DIMKC» [6] (рис. 1), представляющей собой иерархическую схему информационных переделов, в которой каждый последующий уровень добавляет определенные семантические свойства
к предыдущему уровню.

Рис. 1. Методологическая схема информационных трансформаций (информационных переделов),
возникающих в процессе управления знаниями (модель DIMKC)
Fig. 1. Methodological scheme of information transformations (information redistribution)
arising in the process of knowledge management (DIMKC model)
На основании этого представления Л. Прусаком и Т. Давенпортом [7] была осуществлена одна из первых успешных попыток формального количественного описания элементарных компетенций работника. Авторы [7] предложили количественно учитывать возможность конкретного сотрудника выполнять ту или иную работу как постоянно расширяющуюся в процессе производственной деятельности комбинацию личных образовательных знаний, практического опыта, окружающей контекстной информации, индивидуальных ценностей и интуиции, выражающуюся в том числе в умении вербально описывать проводимые действия.
Это позволило рассматривать текстово-фиксируемые (т. е. проявляющиеся в текстах) индивидуальные компетенции каждого из сотрудников компании как составную величину:
![]() , (1)
, (1)
где K0 – образовательные компетенции работника; K1 – компетенции работника, полученные им в результате предшествовавшей производственной деятельности; K2 – соавторские компетенции работника, представляющие собой компетенции его социального (соавторского) окружения, которые он активно использует в своей работе.
Предпосылкой к дальнейшему созданию методики выявления индивидуальных компетенций работника является понимание вербальности человеческого знания и возможности его фиксации в различного рода текстах, созданных средствами естественного языка [8]. Под текстом здесь и далее понимается письменная (или записанная устная) речь, которая внутренне организована и относительно закончена [9].
Чтобы понимать смысл текста, сотрудник предприятия должен быть компетентен в области используемых в рассматриваемом материале понятий, о чем могут свидетельствовать тексты, сгенерированные им ранее.
Таким образом, решение поставленной задачи определения конкретного набора компетенций сотрудника может быть основано на предположении
о том, что и компетенции высококвалифицированного работника, и требования вакансии могут быть описаны в виде определенных наборов текстов, на основании сравнительного анализа которых можно сделать вывод о соответствии специалиста его будущему рабочему месту. При определении различных компонент компетенций сотрудника различаться будут лишь в типы подлежащих анализу коллекций текстов (табл.).
Сравнительная оценка отдельных составляющих компетенций сотрудника
Comparative assessment of individual components of an employee's competencies
|
Объект анализа |
Компетенции, связанные с образованием |
Компетенции, связанные с опытом работы |
Компетенции, связанные с соавторством |
|
Коллекции текстов, |
Коллекции текстов, |
Коллекции тестов, |
Коллекции текстов работ, упомянутых в работах сотрудника |
Таким образом, представление (1) позволяет свести решение задачи оценки степени соответствия компетенций кандидата на вакансию и требований его будущего рабочего места к решению набора задач по определению степени похожести суммарной коллекции порождаемых работником текстов и коллекций текстов, описывающих его будущее рабочее место.
В первом приближении составные части индивидуальной компетенции соискателя, выявляемые путем анализа порождаемых текстов, рассматриваются как равновесомые. При дальнейшем уточнении описательной модели представления (1) отдельному изучению должны быть подвергнуты процессы редукции компетенций работника [10, 11], связанные как
с временем, прошедшим после генерации им конкретного текста (особо характерные для компетенций, связанных с образованием и опытом работы), так и связанные с соавторством. Указанное влияние редукции может быть учтено введением соответствующих коэффициентов при включении конкретных текстов в результирующую коллекцию.
Использование векторного представления текстов для анализа семантической близости коллекций, характеризующих кандидата на вакансию и требования рабочего места
Методологической основой проведения дальнейшего анализа является понимание того, что тексты, сгенерированные на естественном языке, предполагают разную (но определенную) встречаемость слов.
Для проведения подобных процедур сравнения используется векторная модель представления текста (Vector Space Model, VSM). Генерация VSM производится путем представления каждого слова из текста, подвергаемого анализу, в виде многомерного вектора, элементами которого являются слова, используемые во всей выборке.
Существенным является предположение о том, что на содержание текста оказывает влияние лишь частотность использования в нем тех или иных слов, а не места их расположения в тексте.
В этой связи коллекцию подвергаемых анализу текстов можно представить как выборку пар «текст – слово» (d, w), где d Î D, w Î W, D – множество текстов коллекции, W – множество уникальных терминов этой коллекции (именуемое также используемым словарем).
Одним из простейших способов генерации VSM является «one-hot»-кодировка. Чтобы определить
с ее помощью важность конкретного слова в анализируемом тексте, возможно подсчитать, сколько раз унифицированная форма этого слова встречается
в тексте, на основании чего определить его смысловую важность, учитывая тот факт, что чем чаще слово встречается в конкретном тексте, тем выше его важность для него (рис. 2).
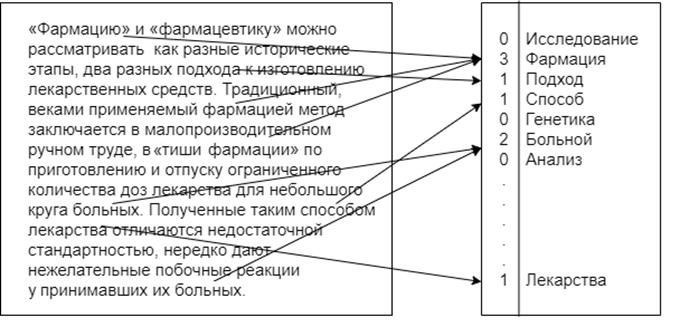
Рис. 2. Определение частотного распределения слов в тексте
Fig. 2. Determining the frequency of word distribution in the text
После того, как у рассматриваемого текста определены веса всех исследуемых слов (в том числе не встречающихся в тексте), возможно построить многомерный вектор, представляющий конкретный текст в векторном пространстве:
![]() ,
,
где dj – векторное представление j-го текста; wij – вес i-го слова в j-м тексте; n – общее количество различных слов во всех текстах коллекции.
При «one-hot»-кодировке вектор, описывающий конкретное слово, состоит из одной единицы, соответствующей положению слова в словаре,
и остальных нулей. Очевидно, что такое сильно разреженное представление неэффективно по памяти и не позволяет сравнивать слова на предмет семантической близости.
Дальнейшим развитием подходов к созданию VSM стало семейство решений, позволяющих создавать низкоразмерное представление каждого слова по набору анализируемых текстов, а также учитывать контекстуальное подобие слов. Среди таких наиболее производительных методов можно назвать Global Vectors (GloVe), созданный в Стэнфордском университете, а также Word2Vec и Bert, разработанные компанией Google [12]. Указанные методы векторного представления не только могут самостоятельно решать задачи приведения слов к их базовой унифицированной форме (лемме), но и способны учитывать их смысловое подобие, а также различать схожие по написанию слова, встречающиеся в разных контекстах; общепринятые сокращения и аббревиатуры являются для таких представлений объектами, равнозначными словам, формирующим текст. Таким образом, использование высокоуровневых векторных представлений позволит решать широкий круг прикладных задач обработки текстов.
В связи с тем, что и анализируемая коллекция текстов, созданных соискателем, и коллекция текстов, описывающих требования его будущего рабочего места, как правило, характеризуются не слишком большим объемом исходных текстовых данных, при построении методики сравнения для получения векторных представлений возможно использовать языковую модель Global Vectors for Word Representation (GloVe) [13] (далее M).
Так как при проведении анализа используются неразмеченные данные, алгоритм GloVe эффективно применяет статистические особенности совпадений отдельных смысловых элементов текста, минимизируя разницу между логарифмом вероятности совместного появления слов и произведением их векторов, используя метод стохастического градиентного спуска. Это позволяет учесть совместную контекстную встречаемость слов в анализируемых текстах и сгруппировать вектора слов по глобальной схожести.
Используя описанные механизмы, подвергнем процедуре сравнения коллекцию научных текстов A, представленных соискателем вакансии, и коллекцию R, состоящую из текстов, содержащих описание исследовательского проекта, фактически представляющих собой набор квалификационных требований к кандидату.
Возможную близость компетенций кандидата
и требований вакансии вычислим через определение косинуса угла между фактическими направлениями многомерных векторов a и r, сгенерированных на основании коллекций A и R, учитывая тот факт, что чем меньше угол между рассматриваемыми векторами, тем выше смысловая близость сравниваемых коллекций текстов.
После обработки коллекции текстов A на языковой модели M определим направление семантического вектора для коллекции текстов соискателя вакансии:
а = M(R), ∀ a ∈ A,
где a – искомый вектор коллекции текстов соискателя; M(A) – обработанная при помощи предобученной модели GloVe коллекция текстов соискателя.
Следующим шагом определим подобный вектор для профессиональных требований к кандидату на открывающуюся вакансию:
r = M(R), ∀ r ∈ R,
где r – искомый вектор коллекции текстов, описывающих требования вакансии; M(R) – обработанная при помощи предобученной модели GloVe коллекция текстов, описывающих компетентностные требования вакансии.
После этих процедур вычислим интересующую нас косинусную меру смысловой близости sim(a, r) для векторов a и r, формально характеризующую степень близости компетенций соискателя и компетентностых требований вакансии:
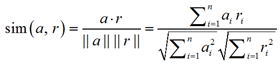 , (2)
, (2)
где ai, ri являются компонентами векторов A и R.
Близость косинусной меры к единице будет говорить о близости сравниваемых векторов, а значит, и свидетельствовать о степени соответствий компетенций соискателя требованиям вакансии проекта. Очевидно, что при подобной оценке нескольких соискателей вакансии предпочтение должно быть отдано тому, у которого значение косинусной меры, вычисленной по выражению (2), выше.
Однако при производстве подобного сравнения следует учитывать тот факт, что полученный интегральный результат плохо поддается интерпретированию полученного расчетного показателя, поскольку специалисту hr-подразделения остается непонятным, на основании присутствия каких компетенций предпочтение в конце концов было отдано тому или иному кандидату. Поэтому применение подобной процедуры предпочтительно для построения программных решений, осуществляющих сравнение интегральных компетенций работников «массовых специальностей», а также молодых специалистов.
Повысить степень интерпретируемости получаемого результата сравнения возможно, применяя подходы, основанные на тематическом моделировании текстов, которые позволяют не только осуществить подобное сравнение, но и обеспечить приемлемую для принятия управленческих решений тематическую интерпретируемость результата.
Применение методов тематического моделирования для анализа семантической близости коллекций текстов, характеризующих компетенции кандидата на вакансию
Основной идеей тематического моделирования текстов является представление о том, что наличие каждого конкретного термина в рассматриваемом тексте автора обусловлено необходимостью детального описания в тексте некоторой смысловой темы, неотъемлемой частью контента которой является рассматриваемый термин.
Как и в описанном ранее случае семантического анализа, любой текст автора представляется в виде некоторого неупорядоченного множества слов, для которого существенным является лишь факт наличия слова в исследуемом тексте, а не его конкретное место в лингвистической конструкции. Процесс анализа текста с применением средств тематического моделирования текстов строится на основании предположений о том, что вхождение конкретного слова w в текст d однозначно обосновано некоторой тематикой t из заданного множества тематик T
и не зависит от самого текста d, а определяется лишь его тематикой, что может быть описано единым распределением вероятности
p(w│t) = p(w│t, d),
где p – распределение вероятности.
В такой постановке исследуемые коллекции текстов (характеризующих научные разработки высококвалифицированного специалиста и требования его будущего рабочего места) могут быть рассмотрены как выборки троек (wi, di, ti), i = 1, … , n из дискретного распределения p(w, d, t) на конечном множестве декартова произведения W × D × T, элементами которого являются все возможные упорядоченные тройки исходных элементов.
В каждой из рассматриваемых троек слова wi
и тексты di являются наблюдаемыми переменными, а конкретные темы из общего множества тем
ti Î T являются скрытыми (латентными) переменными, которые необходимо определить.
Каждый текст в рассматриваемом случае может быть представлен как некоторое дискретное распределение на множестве тем θtd = p(t|d), а каждая латентная тема – как дискретное распределение на множестве слов φwt = p(w|d) (рис. 3).
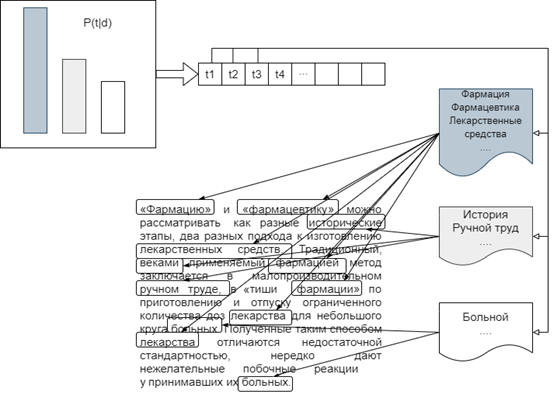
Рис. 3. Схема работы тематического моделирования текста
Fig. 3. Graph of work of thematic text modeling
В этом случае, по теореме о полной вероятности [14], окажется справедливым следующее:
![]() (3)
(3)
С учетом (3) задача построения тематической модели сводится к определению p(w│t) для всех t Î T и p(t│d) для всех d Î D.
После этого, воспользовавшись предположением о том, что распределение слов в конкретной коллекции связано только с темами, а не с текстами, определим логарифм функционала правдоподобия для вероятности совместного появления текста d и слова w в анализируемой коллекции D:
![]() (4)
(4)
при наличии естественных ограничений
![]()
Для решения задачи (4) используем, в частности, эффективный итерационный двушаговый алгоритм EM (Expectation-maximization algorithm), широко применяемый при решении задач математический статистики для определения оценок максимального правдоподобия параметров, при наличии у анализируемой модели предполагаемой зависимости от ряда скрытых переменных [15]. Следует иметь в виду, что методы тематического моделирования также самостоятельно проводят предварительную подготовку текстов, связанную с леммированием.
В настоящее время разработано большое количество разнообразных алгоритмов создания решений по анализу больших объемов текстовых коллекций с использованием методик тематического моделирования, которые имеют определенные особенности применения: латентно-семантический анализ (Latent Semantic Analysis, LSA) [16], латентное размещение Дирихле (Latent Dirichlet Allocation, LDA) [17], вероятностный латентно-семантический анализ (Probabilistic Latent Semantic Analysis, PLSA) [18], темпоральные тематические модели (Dynamic topic models) [19] и др.
В настоящее время подобные алгоритмы успешно используются для потокового анализа социальных сетей, в системах выдачи рекомендаций,
в большом количестве адаптивных справочных систем. При автоматизации процедур рекрутинга использование методов тематического моделирования представляется особенно предпочтительным при необходимости разработки автоматизированных решений, предназначенных для выявления конкретных компетенций работника в достаточно узкой предметной области.
Применение методов иерархического тематического моделирования анализа семантической близости коллекций текстов, характеризующих компетенции кандидата на вакансию
Признавая высокую результативность тематического анализа профессиональных текстов, характеризующих компетенции высококвалифицированных специалистов, следует отметить, что в условиях управления динамичным и большей частью мультидисциплинарным бизнесом часто требуются механизмы, осуществляющие семантическую обработку текстов на более высоком уровне, позволяющем подробно классифицировать смысловую «подисциплинарную» принадлежность тех или иных тем в конкретных текстах.
Это в первую очередь связано с тем, что при управлении современным инновационным предприятием, включающем формулирование целей, распределение задач, учет возможных рисков, контроль производственных процессов и управление персоналом, фактически параллельно используются два подхода к менеджменту: проектный и функциональный.
Обычно считают, что для инновационных предприятий более всего характерно тяготение к проектному подходу, поскольку деятельность каждого сотрудника такой компании не может быть раз и навсегда четко формализована, и ему приходится работать в условиях постоянных изменений и значительной неопределенности. В связи с этим управленческая структура подобными процессами в большей своей части выстраивается не в виде конкретных процессов или функций, а как некоторый набор работ над конкретной задачей, имеющей даты начала и окончания.
Функциональный подход, основанный на профессиональном принципе распределения труда, где каждый участник производственного процесса четко понимает границы своей ответственности, обеспечивает повышение производительности работ, минимальные издержки на менеджмент, высокую управляемость бизнес-процессов, а следовательно, и высокую эффективность компании.
Поэтому у большинства инновационных компаний наблюдается повышенный интерес к более структурированному (в сторону дифференциации конкретных областей знаний) подходу к определению компетенций сотрудников.
В этой связи становится востребованным построение средств анализа компетенций сотрудников, производимое на основании анализа генерируемых ими текстов, позволяющее более точно кластеризовать монодисциплинарные навыки специалистов (рис. 4), используя для этого методы иерархического тематического моделирования [20].
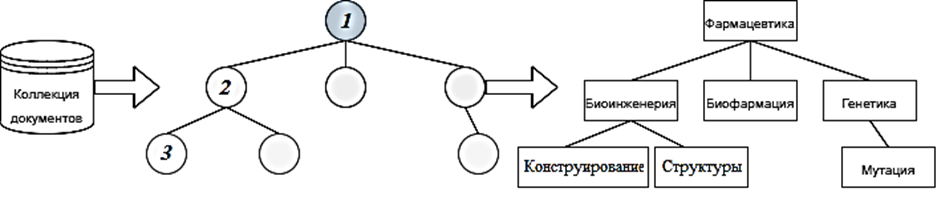
Рис. 4. Построение дисциплинарных тематических иерархий:
1 – корневая вершина; 2 – родительские вершины; 3 – дочерние вершины
Fig. 4. Building the disciplinary thematic hierarchies:
1 – root vertex; 2 – parent vertices; 3 – child vertices
Для построения простейшей иерархии возможно использовать способы, применяемые для плоской кластеризации [21], переходя от понятия «Bag of Words» к понятию «Bag of Topics». Для адекватного построения иерархии тем требуется введение нескольких регуляризаторов, учитывающих ряд дополнительных требований, накладываемых на результирующую модель.
При переходе к нижележащему уровню, который характеризуется множеством содержащихся в нем тем S, генерируется тематическая модель, которая объясняет появление конкретных слов wi в конкретных текстах dj, входящих в анализируемую коллекцию с помощью разложения
![]() ,
,
где распределение p(t|d) известно, поскольку родительский уровень при переходе к дочернему оказывается уже построенным.
В качестве производительных методов иерархического тематического моделирования для анализа коллекций текстов соискателей могут быть использованы hLDA – hierarchicial Latent Dirichlet Allocation (иерархический LDA) [22], HDP – Hierarchical Dirichlet Processes [20], splitLDA [23], STROD – Scalable Recursive Orthogonal Decomposition [24]. Указанные методы иерархического тематического моделирования оказываются наиболее полезными при создании автоматизированных процедур отбора кандидатов на выполнение инновационных работ смешанной дисциплинарности.
Заключение
В результате проведенного аналитического обзора можно сделать следующие выводы, существенные для проведения дальнейших работ по созданию практических автоматизированных методов оценки компетенций сотрудников предприятий:
– указанные компетенции специалиста могут быть формально описаны через набор речевых концептов, содержащихся в коллекциях текстов, порождаемых работником, и коллекции текстов, с которыми он взаимодействовал ранее.
1. Zaporozhec A. S. Innovacionnye predpriyatiya i ih osobennosti s poziciy ekonomicheskoy nauki // Innovacii i investicii. 2020. № 10. S. 3-6.
2. Korkina T. A., Zotova E. N. Zarubezhnyy i otechestvennyy opyt podbora personala // Obschestvo, ekonomika, upravlenie. 2021. T. 6, № 4. S. 58-63. DOI:https://doi.org/10.47475/2618-9852-2021-16408.
3. Solow R. M. A contribution to the Theory of Eco-nomic Growth // Quarterly Journal of Economic. 1956. Iss. 70. P. 65-94.
4. Arrow K. J. The Economic Implications of Learning by Doing // Review of Economic Studies. 1962. V. 29. P. 155-173.
5. Lucas R. E. On the Mechanics of Economic Devel-opment // Journal of Monetary Economics. 1988. 22, July. P. 3-42.
6. Cvetkov V. Ya. Informacionnoe upravlenie. KG, Saarbrϋcken, Germany: LAP LAMBERT Academic Publishing GmbH&Co, 2012. 201 p.
7. Davenport T., Prusak L. Working Knowledge // Harvard Business Review Press, 2000, 240 p.
8. Mashina E. Uniform Assessment of The Company's Employee's Competence Using Natural Language Processing Methods for Their Further Use in Corporate Knowledge Management Systems // Proceedings of FRUCT'32 - 2022. V. 2. P. 374-381.
9. Gal'perin I. R. Tekst kak ob'ekt lingvistiche-skogo issledovaniya. M.: KomKniga, 2007. 144 s.
10. Druzhinin V. N. Psihologiya obschih sposobno-stey. SPb.: Piter, 2007. 368 s.
11. Kutergina E. A., Sanina A. G. Kompetentnostnye profili chinovnikov v sovremennoy Rossii // Zhurnal issledovaniy social'noy politiki. 2017. № 15 (1). S. 113-128.
12. Ponkin D. I. Koncept predobuchennyh yazykovyh modeley v kontekste inzhenerii znaniy // International Journal of Open Information Technologies. 2020. V. 8, no. 9. P. 18-27.
13. Howard J., Ruder S. Universal Language Model Fine-tuning for Text Classification // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne, 2018. P. 328-339.
14. Dolgov A. I. Korrektnye modifikacii formuly Bayesa dlya parallel'nogo programmirovaniya // Superkomp'yuternye tehnologii: materialy 3-y Vseros. nauch.-tehn. konf. Rostov n/D., 2014. T. 1. S. 122-126.
15. Neal R. M., Hinton G. E. A view of the EM algo-rithm that justifies incremental, sparse, and other variants // Learning in Graphical Models. Cambridge, MA: MIT Press, 1999. P. 355-368.
16. Dirvester S., Dumay S., Fernas D., Landauer T., Harshman R. Indexing using hidden semantic analysis // Journal of the American Society of Information Sciences. 1990. V. 41 (6). P. 391-407.
17. Blei D. M., Ng A. Y., Jordan M. I. Latent Dirichlet allocation // Journal of Machine Learning Research. 2003. V. 3, no. 4, 5. P. 993-1022.
18. Korshunov A., Gomzin A. Tematicheskoe modeli-rovanie tekstov na estestvennom yazyke // Tr. In-ta sistem. programmirovaniya RAN. 2012. S. 215-242.
19. Blei D. M, Lafferty J. D. Dynamic topic models // Proceedings of the 23rd International Conference on Ma-chine learning ICML'06, 2006. P. 113-120. DOI:https://doi.org/10.1145/1143844.1143859.
20. Zavitsanos E., Paliouras G., Vouros G. A. Non-Parametric Estimation of Topic Hierarchies from Texts with Hierarchical Dirichlet Processes // Journal of Machine Learning Research. 2011. V. 12. P. 12749-2775.
21. Aduenko A., Kuz'min A., Strizhov V. Vybor priznakov i optimizaciya metriki pri klasterizacii kollekcii dokumentov // Izv. Tul's. gos. un-ta. Estestvennye nauki. 2012. Vyp. 4. S. 119-131.
22. Blei D. M., Jordan M., Tenenbaum J. Hierarchical Topic Models and the Nested Chinese Restaurant Process. NIPS, 2003. 8 p. URL: https://www.cs.columbia.edu/~blei/papers/BleiGriffithsJordanTenenbaum2003.pdf (data obrascheniya: 14.01.2023).
23. Pujara J., Skomorch P. Large-Scale Hierarchical Topic Models // NIPS Workshop on Big Learning. 2012. P. 826-839.
24. Wang C., Liu X., Song Y., Han J. Towards Interac-tive Construction of Topical Hierarchy: A Recursive Tensor Decomposition Approach // Proc. 2015 ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (KDD’15), August 2015. P. 1225-1234.
