










Russian Federation
In this paper, the solution of an urgent scientific and technical problem in the field of information security is considered – the problem of detecting electromagnetic radiation generated by computer technology, within the framework of a structural and linguistic approach to the analysis of experimental data. The implementation of the stage of assigning segmented sections of spectrograms of symbols of some alphabet corresponding to certain types of behavior is considered in detail. As well as the implementation of the analysis stage of the received sequences of symbols. A model of morphological grammar construction and a mechanism for generating texts that differ little from the correct ones are described. The grammar formation stage was implemented in the Python 3.7 programming language. The choice of this programming language is justified by its cross-platform nature, low entry threshold, as well as wide application: from automation of mathematical calculations and machine learning, to the development of web applications. Also, one of the advantages of this language is the availability of many high-quality libraries, including those used for current development. A statistical experiment was conducted to evaluate the effectiveness and accuracy of the developed algorithms. An estimate of the probability of the correct classification of linguistic chains of experimental spectrogram curves into the desired groups and a general assessment of the accuracy of the correct determination of all curves into the desired groups is given. As a result of the application of a structural-linguistic approach to the problem of detecting electromagnetic radiation generated by computer technology, it can be concluded that the obtained linguistic descriptions of the studied spectrograms represent short and reliable rules for their analysis and allow for high accuracy in automated mode to determine deviations in the observed spectra from the specified standards.
computer technology, electromagnetic radiation, structural-linguistic approach, spectrogram, grammar formation, classification
Введение
В настоящее время актуальной научно-технической задачей в области информационной безопасности является задача обнаружения электромагнитных излучений, создаваемых вычислительной техникой [1–5]. В данной работе рассмотрено решение этой задачи в рамках структурно-лингвистического подхода к анализу экспериментальных данных, основные идеи которого рассмотрены в [6, 7].
Структурно-лингвистический подход предполагает последовательность реализации трех основных этапов обработки спектрограмм: выделения и распознавания характерных участков (сегментация); присвоения выделенным участкам символов некоторого алфавита, соответствующих определенным типам поведения кривой (формирование грамматики); анализа полученных последовательностей символов.
Первый этап реализован и представлен авторами в [8, 9]. Данная статья является продолжением исследований и посвящена реализации второго
и третьего вышеуказанных этапов. В рамках второго этапа набор присваиваемых символов представляет собой алфавит, в котором компоненты являются кодовыми обозначениями поведения кривой на каждом участке. Для формирования такого алфавита необходимо применять алгоритмы автоматической классификации, которые будут осуществлять распределение массивов векторов на классы, количество которых определяется самим алфавитом, и устанавливать критерии, по которым каждый новый вектор будет распределен в тот или иной класс, иными словами, присваивать им конкретные символы.
В качестве массива экспериментальных данных для реализации процедуры формирования грамматики послужили спектрограммы электромагнитных излучений, полученные с помощью программно-определяемой радиосистемы на базе RTL2832 и R820T в ГОУ ВПО «Донецкий национальный университет».
Программно-определяемые радиосистемы (SDR) представляют собой набор программных и специальных аппаратных средств, которые позволяют решать круг задач анализа взаимодействия радиоизлучений в широком диапазоне частот. Некоторые SDR системы могут использоваться для решения задач мониторинга спектра радиочастот [10, 11]. Данный класс устройств, благодаря возможностям программного управления, реализует функции физического уровня, что обеспечивает возможность обработки различных типов сигналов без изменения аппаратной части принимающего устройства.
На рис. 1 показан процесс выявления и регистрации электромагнитных излучений и образец получаемых спектрограмм.
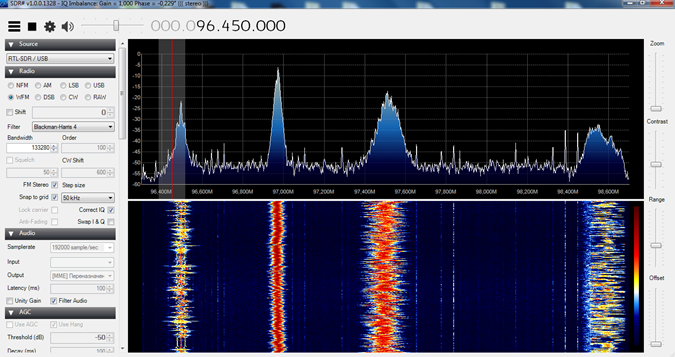
Рис. 1. Визуализация спектра радиообстановки
Fig. 1. Visualization of the radio spectrum
Формальная постановка задачи
В результате выполнения первого этапа, а именно последовательного применения алгоритмов сегментации и классификации выделенных фрагментов [8, 9], анализируемая спектрограмма визуализируется в виде ряда из символов некоторого конечного алфавита. Ряд такого вида целесообразно рассматривать как некоторый текст T на неизвестном языке J (специальным образом адаптированном для точного описания анализируемых спектрограмм), а каждую последовательность символов текста T (цепочку) целесообразно рассматривать как некоторую фразу на данном языке.
Для описания получаемых спектрограмм зададим следующий алфавит: нарастание сигнала (передний фронт) обозначим символом L (left), высокий уровень сигнала (центральная часть) – C (central), спад сигнала (задний фронт) – R (right). Учет фоновых (неинформативных) участков в данном этапе не рассматривается. Таким образом, сформирован алфавит языка описания исследуемых спектрограмм, состоящий из трех символов ![]() .
.
С такой точки зрения задачу формирования языка описания спектрограмм электромагнитных излучений, создаваемых вычислительной техникой, можно сформулировать следующим образом:
– задано некоторое количество текстов T в виде массива рядов символов;
– необходимо сформировать словарь D из отдельных лингвистических единиц (стабильных последовательностей символов);
– необходимо представить каждый из обрабатываемых текстов T в виде одного или нескольких слов этого словаря D.
Учитывая вышесказанное, пусть имеется всего один текст ![]() большой длины. Каждая пара индексов
большой длины. Каждая пара индексов ![]() исключает из текста T некоторый сегмент последовательности, образующийся посредством удаления в T символов с индексами, меньшими i и большими j:
исключает из текста T некоторый сегмент последовательности, образующийся посредством удаления в T символов с индексами, меньшими i и большими j: ![]() . Каждому сегменту s соответствует образ – ряд его символов, у которых удалены данные о местоположении этого сегмента (индексы) в тексте T. Очевидно, что в тексте может иметься несколько сегментов, соответствующих одному образу. Необходимо найти такие наборы образов, из которых можно составить заданный текст T. Один из таких наборов и есть искомый словарь D.
. Каждому сегменту s соответствует образ – ряд его символов, у которых удалены данные о местоположении этого сегмента (индексы) в тексте T. Очевидно, что в тексте может иметься несколько сегментов, соответствующих одному образу. Необходимо найти такие наборы образов, из которых можно составить заданный текст T. Один из таких наборов и есть искомый словарь D.
Процедура формирования грамматики
Разделение S текста T на непересекающиеся сегменты формирует некоторый словарь D(S). Такое формирование словаря D(S) можно рассматривать как выявление набора триггеров изменений состояний исследуемого процесса, которые отражены в символическом представлении спектрограмм в виде стабильных последовательностей символов. Например, в задаче идентификации речи в условиях помех [12] такого рода символы можно рассматривать как минимальные смыслоразличительные единицы языка (фонемы). В таких условиях выделение фонем в сигнале речи рассматривается не как процедура сегментации, а как процедура его структурно-лингвистического анализа.
Пусть D – словарь, в котором J – множество всех конечных последовательностей символов T из алфавита A (язык), тогда подмножество ![]() является подмножеством всех последовательностей T, представляющих собой последовательность слов из словаря D. Таким образом,
является подмножеством всех последовательностей T, представляющих собой последовательность слов из словаря D. Таким образом, ![]() – язык, детерминированный словарем D. Последовательность T считается правильной последовательностью языка
– язык, детерминированный словарем D. Последовательность T считается правильной последовательностью языка ![]() тогда и только тогда, когда имеется такое ее разбиение S, что образ каждого сегмента из S является словом из D. Любой такой язык, каждая последовательность слов из D которого является правильной последовательностью, считается языком с морфологической грамматикой. Для использования такой морфологической грамматики при анализе других текстов T, т. е. других экспериментальных данных, необходимо применять процедуру преобразования символьного текста в упорядоченный набор слов или же процедуру разбиения текста T на слова из словаря D. Иными словами, необходима процедура верного распознавания этого текста на языке
тогда и только тогда, когда имеется такое ее разбиение S, что образ каждого сегмента из S является словом из D. Любой такой язык, каждая последовательность слов из D которого является правильной последовательностью, считается языком с морфологической грамматикой. Для использования такой морфологической грамматики при анализе других текстов T, т. е. других экспериментальных данных, необходимо применять процедуру преобразования символьного текста в упорядоченный набор слов или же процедуру разбиения текста T на слова из словаря D. Иными словами, необходима процедура верного распознавания этого текста на языке ![]() .
.
Однако исследуемые спектрограммы не всегда представляются в виде правильных текстов достаточно точно. В контексте рассматриваемой задачи такая процедура осуществляется с целью автоматизации анализа экспериментальных данных спектрограмм, которые изменяют свое состояние случайно, т. е. без какой-либо определенной закономерности, в том числе и применение алгоритмов сегментации и классификации на предшествующем этапе может вносить эффект случайности в формируемые лингвистические последовательности. Исходя из этого такую морфологическую грамматику следует расценивать как модель выбора оптимальной аппроксимирующей функции для текстов, которые формируются экспериментальными данными спектрограмм.
Для полноценного ее использования процедуру генерации правильных текстов необходимо расширить некой искажающей процедурой, которая будет генерировать последовательности, мало отличающиеся от правильных. Для ее реализации следует ввести меру сходства двух случайных последовательностей из одного алфавита А, которая будет являться степенью искажения при переходе между последовательностями. В качестве процедуры искажения может применяться трансформационная грамматика, которая будет содержать некое множество элементарных трансформаций,
т. е. минимальных искажений. Процедура построения трансформационной грамматики подробно описана в [6, 7]. Тогда мерой сходства между двумя последовательностями целесообразно выбрать минимальное число элементарных трансформаций, необходимых для перехода от одной последовательности к другой.
Рассмотрим некий нечеткий язык F, в котором язык ![]() является его ядром. Язык F определяется как
является его ядром. Язык F определяется как ![]() , где G – некая трансформационная грамматика, определяющая меру сходства
, где G – некая трансформационная грамматика, определяющая меру сходства ![]() случайной последовательности
случайной последовательности ![]() от последовательности ядра
от последовательности ядра ![]() . Тогда мерой различия последовательности T языку F является величина
. Тогда мерой различия последовательности T языку F является величина
![]() (1)
(1)
В таком случае задача анализа текста T сводится к задаче нахождения для последовательности
T такой последовательности слов ![]() из словаря М, чтобы мера отличия (1) последовательности T от ядерной последовательности
из словаря М, чтобы мера отличия (1) последовательности T от ядерной последовательности ![]() принимала значение минимума на всем множестве существующих ядерных последовательностей. Описанная задача представляет собой своего рода аналог задачи поиска строгого разбиения текста на слова, а сформированная в результате ее решения последовательность символов либо слов принимается окончательным лингвистическим описанием анализируемой спектрограммы.
принимала значение минимума на всем множестве существующих ядерных последовательностей. Описанная задача представляет собой своего рода аналог задачи поиска строгого разбиения текста на слова, а сформированная в результате ее решения последовательность символов либо слов принимается окончательным лингвистическим описанием анализируемой спектрограммы.
Результаты построения цепочек
Этап формирования грамматики был реализован на языке программирования Python 3.7. Выбор языка обоснован простотой синтаксиса и большим набором библиотек. При выборе библиотек учитывались скорость работы, использование вычислительных мощностей, а также простота использования (pandas, numpy, matplotlib, scipy).
Результаты формирования первых 15 разборов, их объединяющих и эталонных цепочек при 4 разных состояниях спектрограмм, приведены на рис. 2.

а
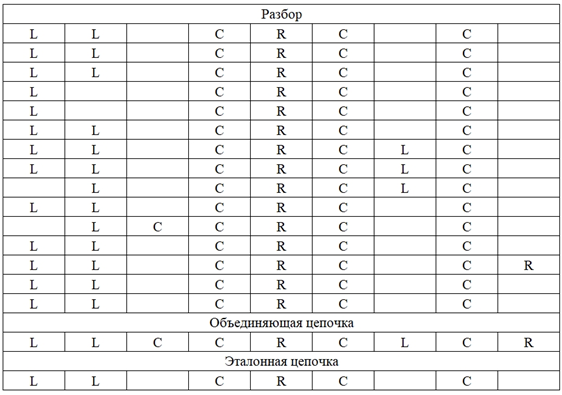
б
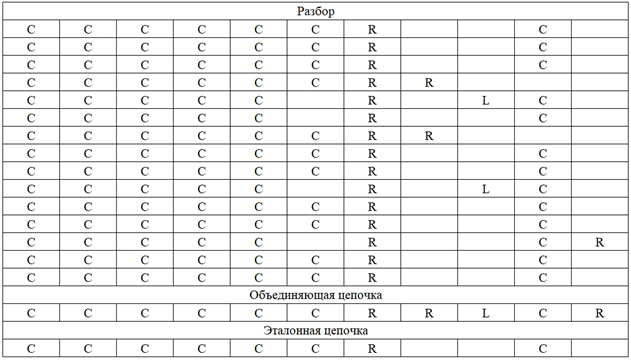
в
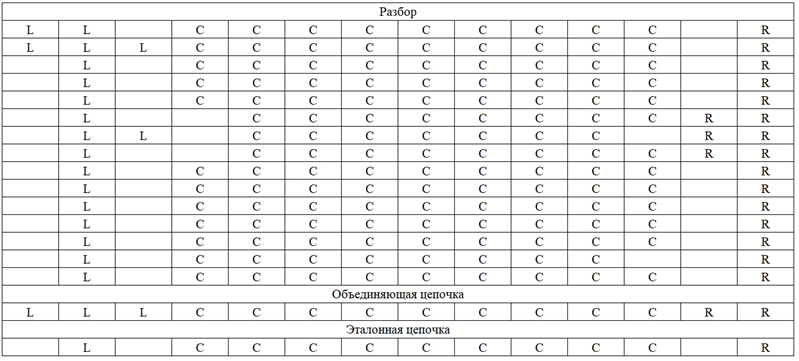
г
Рис. 2. Сформированные лингвистические цепочки:
а – без подавления; б – с подавлением 1-го сигнала;
в – 2-х сигналов; г – 3-х сигналов
Fig. 2. Formed linguistic chains:
a – without suppression; б – with suppression
of the 1st signal; в – 2 signals; г – 3 signals
Анализ полученных последовательностей
и оценка эффективности разработанных алгоритмов
Для оценки эффективности и точности разработанных алгоритмов проведен статистический эксперимент. В табл. 1 приведена оценка вероятности верной классификации лингвистических цепочек экспериментальных кривых спектрограмм в нужные группы (n – количество кривых, A – точность верной классификации).
Таблица 1
Table 1
Оценка вероятности верной классификации
Estimation of the probability of correct classification
|
Группа |
1 группа |
2 группа |
3 группа |
4 группа |
|
||||
|
n, % |
A, % |
n, % |
A, % |
n, % |
A, % |
n, % |
A, % |
|
|
|
1 группа |
66 |
100 |
80 |
70 |
100 |
50 |
6 |
40 |
|
|
20 |
90 |
14 |
60 |
88 |
30 |
|
|||
|
14 |
80 |
6 |
50 |
6 |
10 |
||||
|
2 группа |
20 |
70 |
60 |
100 |
6 |
60 |
100 |
30 |
|
|
60 |
60 |
26 |
90 |
80 |
50 |
|
|||
|
20 |
50 |
14 |
80 |
14 |
40 |
||||
|
3 группа |
100 |
50 |
60 |
60 |
54 |
100 |
60 |
50 |
|
|
20 |
50 |
40 |
90 |
||||||
|
40 |
40 |
||||||||
|
20 |
40 |
6 |
80 |
||||||
|
4 группа |
6 |
40 |
6 |
40 |
6 |
60 |
60 |
100 |
|
|
74 |
30 |
86 |
30 |
74 |
50 |
26 |
90 |
|
|
|
20 |
10 |
6 |
20 |
14 |
40 |
14 |
80 |
|
|
В табл. 1 по вертикали и горизонтали приведены наименования групп, на пересечениях указаны вероятности и точность верной классификации кривых исследуемых спектрограмм из одной группы в другую. Таким образом, 66 % кривых первой группы со 100 % точностью определены в первую группу, 20 % – с 90 % точностью, 14 % – с 80 % точностью и т. д. В качестве критерия точности принята мера сходства (1) анализируемых цепочек с эталоном группы, где 100 % – полное совпадение. Из анализа табл. 1 следует, что минимальная точность, при которой кривая верно определена в нужную группу, составляет 80 %.
В табл. 2 приведена общая оценка точности верного определения всех кривых в нужные группы.
Таблица 2
Table 2
Общая оценка точности верной классификации
General assessment of the accuracy of the correct classification
|
Группа |
1 группа, A, % |
2 группа, A, % |
3 группа, A, % |
4 группа, A, % |
|
1 группа |
90 |
60 |
50 |
27 |
|
2 группа |
60 |
90 |
50 |
30 |
|
3 группа |
50 |
50 |
90 |
45 |
|
4 группа |
27 |
30 |
45 |
90 |
В табл. 2 по вертикали и горизонтали приведены наименования групп, на пересечениях указана точность верной классификации кривых исследуемых спектрограмм из одной группы в другую. Таким образом, кривые из первой группы верно определены в первую группу с точностью 90 %, во вторую – 60 %, в третью – 50 %, в четвертую – 27 % и т. д. Из анализа табл. 2 следует, что точность верного определения кривой в нужную группу составляет 90 %.
Заключение
В результате применения структурно-лингвистического подхода к задаче обнаружения электромагнитных излучений, создаваемых вычислительной техникой, можно заключить, что полученные лингвистические описания исследуемых спектрограмм представляют собой короткие и надежные правила для их анализа и позволяют с высокой точностью в автоматизированном режиме определять отклонения в наблюдаемых спектрах от заданных эталонов.
1. Faustov I. S., Tokarev A. B., Sladkih V. A., Koz'min V. A., Kryzhko I. B. Radiokontrol' sluzhebnyh parametrov signalov Bluetooth // Sistemy upravleniya, svyazi i bezopasnosti. 2021. № 3. S. 135-151.
2. Ashihmin A. V., Vinogradov A. D., Rembovskiy A. M., Sladkih V. A. Sposob odnopozicionnogo mestoopredeleniya istochnikov radioizlucheniya s ispol'zovaniem bortovogo radiopelengatora bespilotnogo letatel'nogo apparata vertoletnogo tipa // Sistemy upravleniya, svyazi i bezopasnosti. 2021. № 4. S. 40-57.
3. Tret'yakov I. A., Danilov V. V. Spektral'nyy analiz radiosignalov v real'nom vremeni na osnove primeneniya eho-effekta // Vestn. Astrahan. gos. tehn. un-ta. Ser.: Upravlenie, vychislitel'naya tehnika i informatika. 2022. № 1. S. 53-59.
4. Tret'yakov I. A., Danilov V. V. Issledovanie spektrogramm radiochastot metodami lingvisticheskogo analiza // Vestn. Astrahan. gos. tehn. un-ta. Ser.: Upravlenie, vychislitel'naya tehnika i informatika. 2020. № 3. S. 26-33.
5. Rushechnikov Ya. I., Tret'yakov I. A. Avtomatizaciya procedury obnaruzheniya tehnicheskih kanalov utechki informacii i pobochnyh elektromagnitnyh izlucheniy // Vzaimodeystvie vuzov, nauchnyh organizaciy i uchrezhdeniy kul'tury v sfere zaschity informacii i tehnologiy bezopasnosti: sb. st. po materialam Mezhdunar. konf., posvyasch. pamyati d-ra tehn. nauk, prof. A. A. Tarasova i d-ra tehn. nauk, starshego nauch. sotr. O. V. Kazarina (Moskva, 19-20 aprelya 2022 g.) / pod red. D. A. Mityushina. M.: Izd-vo RGGU, 2022. S. 240-245.
6. Mottl' V. V., Muchnik I. B. Lingvisticheskiy analiz eksperimental'nyh krivyh // TIIER. 1979. T. 69. № 5. S. 12-39.
7. Chistova G. K., Volchihin V. I. Metody i procedury postroeniya lingvisticheskoy sistemy obnaruzheniya i raspoznavaniya narushitelya // Vestn. MGTU im. N. E. Baumana. Ser.: Priborostroenie. 2004. № 3. S. 96-114.
8. Danilov V. V., Tret'yakov I. A., Shalaev A. V., Rushechnikov Ya. I. Algoritmy identifikacii perehodnyh uchastkov eksperimental'nyh krivyh s primeneniem approksimacii // Sb. nauch. tr. DONIZhT. 2018. № 48. S. 19-23.
9. Danilov V. V., Tret'yakov I. A., Rushechnikov Ya. I. Algoritmizaciya prisvoeniya simvolov analiziruemym uchastkam eksperimental'nyh krivyh // Sb. nauch. tr. DONIZhT. 2018. № 51. S. 15-22.
10. Rushechnikov Ya. I., Danilov V. V. Informacionnaya tehnologiya radiomonitoringa na osnove programmno-opredelyaemoy radiosistemy // Vestn. Donec. nacion. un-ta. Ser. G: Tehnicheskie nauki. 2020. № 1. S. 31-36.
11. Rushechnikov Ya. I., Danilov V. V., Borschevskiy S. V. Informacionnaya tehnologiya avtomatizirovannoy lokalizacii istochnika izlucheniya // Vestn. Donec. nacion. un-ta. Ser. G: Tehnicheskie nauki. 2020. № 4. S. 26-34.
12. Tret'yakov I. A., Kozhekina E. N., Syrovackiy V. I. Tekstonezavisimaya identifikaciya rechi v usloviyah pomeh // Vestn. Donec. nacion. un-ta. Ser. G: Tehnicheskie nauki. 2022. № 2. S. 64-77.
