










Россия
Россия
Рассматриваются задача создания модели распознавания объектов на изображениях и возможные способы ее решения на примере работы с российскими дорожными знаками по ГОСТ Р 52290-2004. Проведен анализ способов построения прогностических моделей распознавания изображений, существующих решений в открытом доступе. В качестве базовой модели используется сверточная нейронная сеть. Разработана модель распознавания дорожных знаков на базе трансферной сети YOLOv7 в результате дообучения на наборе данных из российской базы изображений автодорожных знаков RTSD. Проанализированы и описаны метрики оценки качества работы созданной модели. Созданная модель отвечает требованиям качества в отношении объективных метрик, позволяет строить прогнозы с учетом специфических ситуаций в различных погодных условиях и в разное время суток для 146 различных предопределенных классов. Характеристикой класса является номер знака по ГОСТ Р 52290-2004. Модель обладает точностью предсказаний, равной 0,847 при полноте предсказаний в 0,811. Усредненная точность предсказаний модели – 0,884 при тестировании на 493 изображениях из тестовой выборки. Тестовая выборка не пересекается с обучающей, составляющей 1 842 изображения. Разработанная модель опубликована в открытом доступе как для использования в научных целях, так и для дальнейшего дообучения. Это дает возможность исследователям в данной области ознакомиться с практическим примером реализации модели, дополнить или улучшить его при необходимости. Описанный в работе метод позволит исследователям в различных предметных областях найти решение, позволяющее преодолеть ресурсные ограничения при создании высокопроизводительной и качественной прогностической модели распознавания.
дорожные знаки, сверточная нейронная сеть, изображение, точность, архитектура YOLO, тестовая выборка, прогностическая модель распознавания
Введение
Человеческий фактор является одной из основных причин возникновения происшествий во множестве сфер деятельности, в том числе и в области управления транспортными средствами. Полная или частичная автоматизация процессов, задействованных при исполнении повторяющихся задач, позволяет снизить или исключить описанный фактор риска из числа возможных [1]. В список существующих способов автоматизации транспортных средств можно включить как полный отказ от водителя в качестве участника транспортного процесса, так и разработку систем поддержки принятия решений, систем помощи в управлении транспортным средством. Указанные варианты систем имеют право на существование, обладая как недостатками, так и положительными сторонами [2, 3].
При разработке вышеуказанных программных решений, нацеленных на автоматизацию задач с высоким уровнем потенциального риска, в целях безопасности, стабильности и эффективности в распознавании объектов используются модели распознавания данных на изображении, построенные на базе нейросетевых технологий в совместном режиме работы с использованием лидаров, радаров и датчиков [4]. Эти модели, как правило, являются прогностическими, т. е. дают вероятностную оценку принадлежности объекта на изображении к определенному классу на основе метрик, указывая, что на изображении с определенной вероятностью находится именно этот объект в помеченной области. Этот вероятностный прогноз и является основным критерием для отнесения модели к классу прогностических.
Основным стремлением при работе с предметной областью высокого риска и значимости является достижение наибольшей точности модели в ее предсказаниях при стабильно высоком уровне уверенности модели в собственных предсказаниях. Средством к достижению цели является учет совокупности факторов, относящихся как к специфике разработки модели распознавания в целом, так и к предметной области.
В работе рассматривается предметная область – дорожные знаки – как часть домена, исследование которого необходимо для создания системы автоматизированного анализа ситуации на дорожном участке и дальнейшего на нее реагирования. Решаемая в рамках данной работы задача – построение прогностической модели распознавания дорожных знаков, действующих на территории Российской Федерации. Актуальность задачи обусловлена отсутствием моделей распознавания знаков РФ в публичном доступе, невозможностью проведения экспериментов по работе с подобными моделями, включая проведение интеграционного тестирования для создания программного средства, направленного на комплексное решение задач автоматизации анализа и реагирования на дорожном пространстве.
Анализ зарубежных исследований в данной области представляет интерес лишь для понимания принципов построения моделей распознавания, однако в общем виде не имеет практического значения при разработке модели распознавания дорожных знаков РФ ввиду значительных отличий в используемом наборе данных и их классификации. Пример зарубежного исследования приведен в статье [5], где описывается подход к созданию усовершенствованной системы помощи водителю (ADAS). В качестве компонента анализа выступает прогностическая модель распознавания дорожных знаков, построенная на наборе данных German Traffic Sign Recognition Benchmark (GTSRB). Модель обучена
с использованием группы моделей YOLO: YOLOv3 и YOLOv4-tiny. Исследователями было принято решение выполнить балансировку набора данных и уменьшения числа изображений на тестовой и обучающей выборке: с 51 900 до 30 000, с аугментацией полученных данных до 41 900. Для тестирования использовалось 12 570 изображений. В ходе обучения удалось добиться высоких значений метрик – точности accuracy 0,958, f1-меры 0,952 и точности precision 0,91. Однако проверить модель не представляется возможным, т. к. она отсутствует в публичном доступе.
Решению задачи построения прогностической модели распознавания дорожных знаков также посвящен ряд работ российских исследователей. В работах [6, 7] используется устаревший метод анализа изображений – цветовой анализ. Авторы отмечают, что «наблюдается неустойчивость к изменению погодных условий и шумов на изображении, обнаружение схожих с геометрическими фигурами не только дорожных знаков, но и других объектов» [6, c. 114]. Кроме того, анализ работ позволяет сделать вывод, что имеются проблемы с классификацией распознанных знаков. В работе [8] приведен алгоритм распознавания дорожных знаков, основанный на контурном анализе и вычислении расстояний между списками. Как отмечают авторы, алгоритм подвержен влиянию положения знака, не способен идентифицировать его, а также работает от формы – прямоугольной, треугольной, круглой, – что говорит о его низкой универсальности. При этом не определено метрик корректности отработки алгоритма. Со слов авторов, алгоритм «четко детектирует», что является субъективным суждением.
Также предпринимались попытки использовать нейросетевую модель для решения этой задачи, например, в работе исследователей Волгоградского государственного университета [9] приводится решение задачи детектирования дорожных знаков с использованием группы моделей YOLOv8, показавшей высокие результаты усредненной точности на тестовых данных – 0,98. Однако, с нашей точки зрения, этот показатель точности нельзя считать объективным, т. к. выборка данных для тестирования модели очень мала, сама выборка не является взвешенной.
Интересна работа [10] исследователей, ставящих перед собой задачу создания модели распознавания дорожных знаков. На первый взгляд, мы видим, что удалось добиться высокого показателя точности (accuracy) 0,985, однако данная метрика не выражает полноты качества модели, что видно из слов исследователей далее: «...наша модель может справляться лишь с небольшим изменением знаков, на ее работоспособность сильно влияют погодные условия, большое пространство вокруг знаков» [10, с. 1296]. Хотя выборка и представляла собой 35 000 изображений с 43 различными видами дорожных знаков, вариативность выборки мала, не учтены исключительные ситуации. Следует отметить, что исследователи явным образом не конкретизируют используемый набор данных, однако по приложенным изображениям и числовым характеристикам можно предположить, что используется набор данных GTSRB, что говорит о невозможности использования модели со знаками РФ.
Обзор предметной области
Задача распознавания дорожных знаков состоит в нахождении на изображении или видеопотоке знаков дорожного регулирования, что включает как обнаружение позиции знака, так и его классификацию.
Внутри отдельных групп дорожных знаков существует принцип систематизации в рамках распределения внутри описательных правил принадлежности отдельных знаков к конкретной предписываемой категории. Категориальное распределение различается в разных странах как в количественном, так и в качественном соотношении [11].
В работе рассматриваются дорожные знаки, действующие на территории Российской Федерации, описанные в ГОСТ Р 52290-2004 «Технические средства организации дорожного движения. Знаки дорожные. Общие технические требования» [12]. В ГОСТе перечислены требования по описанию конкретных групп знаков, выполнена их систематизация, что позволяет выделить среди них отдельные классы на основе правил регулирования [13].
Определено 8 классов разбиения дорожных знаков: предупреждающие (34 группы знаков, 45 знаков), приоритета (7 групп знаков, 13 знаков), запрещающие (33 группы знаков, 36 знаков), предписывающие (8 групп знаков, 17 знаков), особых предписаний (34 группы знаков, 55 знаков), информационные (19 групп знаков, 30 знаков), сервиса (18 групп знаков, 18 знаков), таблички (22 группы знаков, 56 знаков). Общее количество уникальных знаков – 270, не считая возможных вариаций знаков со звездочкой (множество вариантов). Каждый класс имеет внутреннюю систему разделения – группу, которая формирует подклассы. Эта система разделения представлена иерархической моделью явной классификации.
Как можно судить по рассмотренным ранее работам, важность при работе с предметной областью по дорожным знакам представляют не только внутренние, но и внешние факторы среды. Под такими факторами понимаются различие погодных условий, времени суток, качества изображений и расстояние до знаков [14].
Таким образом, определяющими факторами при работе с предметной областью являются нормативные правила описания объектов типа «дорожный знак», а также совокупность вышеупомянутых внешних факторов.
Требования к модели
При разработке прогностической модели распознавания основными требованиями к разрабатываемой модели являются возможность обработки изображений с учетом двухмерной топологии, инвариантность от масштаба изображений, скорость расчетов. Эти требования могут быть удовлетворены с использованием различных методов построения моделей.
В работе используются сверточные нейронные сети, т. к. они обладают рядом преимуществ, способствующих решению задачи построения модели распознавания дорожных знаков:
– сверточные слои позволяют модели изучать локальные пространственные признаки изображения. Для распознавания дорожных знаков важно учитывать геометрические особенности, текстуры и формы знаков, что хорошо решается с помощью сверточных операций;
– способность к автоматическому извлечению признаков: сверточные сети способны автоматически извлекать значимые признаки изображения на различных уровнях абстракции. Это позволяет модели обучаться на более высокоуровневых признаках, что повышает их способность к обобщению и распознаванию сложных паттернов;
– инвариантность к трансформациям: сверточные сети обладают инвариантностью к сдвигам, масштабированию и поворотам изображений. Это особенно важно в задаче распознавания дорожных знаков, которые могут быть представлены на изображениях в различных ракурсах и условиях освещения;
– эффективное использование параметров: сверточные сети обладают структурой, которая позволяет эффективно использовать параметры модели, что делает их относительно компактными по сравнению с полносвязными нейронными сетями.
Как результат, применение сверточных нейронных сетей для задачи распознавания дорожных знаков позволяет создавать модели, способные эффективно работать с изображениями, извлекать признаки и классифицировать знаки даже в условиях изменчивости и шума.
Фундаментальные принципы, которые используются в архитектуре сверточных нейронных сетей, это свертка и субдискретизация. Эти операции выполняются последовательно и позволяют выделить более высокоуровневые признаки из базовых данных.
Свертка подразумевает поэлементное умножение фрагментов исходных данных на ядро свертки, которое представляет собой матрицу, и последующее суммирование. Таким образом, получается карта признаков. Эту операцию можно также интерпретировать как поиск характеристических признаков, которые затем используются для построения матрицы свертки. При использовании ядер свертки как обучающих параметров выходы из предыдущего слоя образуют сверточный слой. Количество таких слоев в сети может быть разным, в зависимости от конкретной архитектуры сети.
Операция субдискретизации, или пулинга, производится после свертки и используется для уменьшения размеров сформированных карт признаков. При пулинге задействуется либо функция максимума, либо взвешенного среднего. Таким образом формируется пулинговый слой, на основе которого можно достичь инвариантности от масштаба исходных данных, более высокой скорости расчетов.
Сеть состоит из нейронов, обладающих своими весами и смещениями, набором входных данных. Формирование полносвязного слоя основано на том, что каждый нейрон в данном слое имеет полные связи с нейронами в предыдущем слое, принимая входные данные и выдавая выходные данные. При этом выходы нейронов с предыдущего слоя связаны со входами нейронов с текущего слоя, а выходы текущего передаются следующему слою [15].
Исходя из особенностей архитектуры и специфики ее построения, можно считать, что сверточная нейронная сеть удовлетворяет требованиям рассматриваемой задачи построения прогностической модели: при работе со сверточной сетью учитывается двухмерная топология изображений, сеть устойчива к смещениям, изменениям масштаба и поворотам объектов.
Определение подхода при создании модели распознавания
По результатам анализа подходов к решению задачи распознавания объектов на изображении был выбран метод реализации модели на основании сверточной нейронной сети, предобученной на некотором множестве изображений. Такой тип сверточных сетей принято называть трансферными. Данный метод позволяет значительно сократить время разработки модели без потерь точности, а также осуществить разработку модели при недостаточном количестве машинных ресурсов [16].
Один из подходов, базирующихся на сверточных нейронных сетях, состоит в использовании канонических изображений классов в качестве ядра. Эти ядра необходимо обнаружить на изображении путем применения скользящего окна: изображение разделяется на квадратные фрагменты – ограничивающие рамки, содержимое которых передается как входные данные. В процессе обработки фрагмент перемещается по изображению, занимая все возможные положения на дискретной плоскости. Вместо использования шаблона можно применять обученный классификатор, но для достижения лучших результатов требуется перебор всех ограничивающих рамок с применением порога уверенности в правильной классификации. Это важно, потому что объекты могут быть разного масштаба и находиться в разных частях изображений. Использование подхода влечет неэффективный полный перебор всех рамок.
Чтобы избежать полного перебора, применяются два параллельно развивающихся подхода: двухэтапные и одноэтапные методы [17]. Принципиальное отличие между ними заключается в том, что в двухэтапных методах используется дополнительный алгоритм генерации регионов – точек интереса, – позволяющий добиться высокой точности. Однако эти методы уступают в значительной мере по скорости одноэтапным методам, что критично для решения задач управления беспилотным автомобилем, распознавания дорожных знаков и им подобным. Популярные представители семейства методов: YOLO [17] и SSD [18].
После проведенного анализа существующих решений определен ряд работ с похожей спецификой, использующих группу моделей YOLO как базу для обучения собственных моделей, например работа [9].
Выбор группы моделей YOLO для решения задачи распознавания дорожных знаков продиктован целями данной задачи, решаемыми благодаря преимуществам указанных моделей: YOLO архитектура изначально разработана для быстрой и эффективной работы на больших наборах данных. Это важно в контексте распознавания дорожных знаков, где скорость работы модели играет ключевую роль для обеспечения безопасности на дороге, в том числе при внедрении созданной модели в ADAS. Архитектура YOLO позволяет находить и классифицировать одновременно несколько объектов на изображении. Дорожные знаки могут принадлежать к разным классам, и применение YOLO позволяет точно определять каждый из них. Архитектура YOLO демонстрирует хорошую точность при работе с изображениями различного качества и условиями освещения, что важно при работе в различных погодных условиях и в различное время суток. Архитектура YOLO имеет много конфигурационных параметров, которые можно настроить под конкретную задачу распознавания дорожных знаков, что делает эту архитектуру очень гибкой и адаптивной.
Метрики валидации модели
Для оценки качества модели необходимо выбрать набор метрик. Выбор должен осуществляться с учетом установленных показателей и требований к модели, определенных на этапе проектирования. К метрикам оценки качества создаваемой модели распознавания относятся:
– полнота предсказаний (отношение числа истинно положительных решений TP к общему количеству решений, включая ложно отрицательные решения FN):
![]() ;
;
– точность предсказаний (отношение числа истинно положительных решений к общему количеству решений, включая ложно положительные решения FP):
![]()
– F1-мера (гармоническое среднее между точностью и полнотой, отношение площадей ограничивающих рамок – IoU, измеряет перекрытие между двумя границами – предсказанной моделью и объявленной изначально):
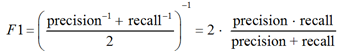
– усредненная точность (рассчитывается как среднее значение средней точности (AP) по всем классам и/или общих пороговых значений IoU в зависимости от определенных задач распознавания):
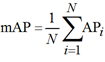 .
.
Заметим, что несмотря на то, что данные метрики описаны в литературе по распознаванию изображений, далеко не во всех исследованиях (например, упомянутых во введении статьи) они используются авторами, что не позволяет получить полного представления о качестве модели.
Эксперименты, проводимые с разрабатываемой моделью, подтвердили достоверность показаний метрик и их общую достаточность в определении качества модели: в первичных экспериментах проведено обучение модели на ранней версии YOLOv6, обучение проводилось на 1 842 изображениях на обучающей выборке и 493 на тестовой выборке. Была произведена объективная оценка на валидирующем наборе, итоговый результат обученной на 35 эпохах модели показал следующие значения метрик: mAP@.5 – 0,668; precision – 0,612. Обучение на модели YOLOv6 за 35 эпох показало худший результат: mAP@.5 – 0,385; precision – 0,42.
Анализ оценки моделей из смежных предметных областей для решения типовой задачи (например, [19, 20]) также показал объективность использования выбранных метрик: согласно исследованию, приведенному в работе [19], удалось оценить полученную модель как надежный детектор и утвердить ее использование с учетом приведенных метрик.
Специфика работы с наборами данных
Чтобы оценить объективность разрабатываемой модели с использованием выбранного подхода, следует учитывать не только показания метрик, но и специфику подбора набора данных. Описывая показатели точности предсказанной модели, полноту ее предсказаний в выставлении оценки качества прогностической модели, необходимо учитывать, что опорой в выставлении оценки служит тестовая выборка данных. Таким образом, объективно оценить две разные модели можно только обладая единым набором данных для теста, иначе показатели можно свести к условно высоким при сужении набора тестовых данных и их усреднении. Для вынесения объективной оценки по качеству модели набор данных должен отвечать определенным правилам и критериям: качество изображений, соответствие изображений стандартизованному снимку или же элементу видеопотока, наличие исключительных ситуаций, его полнота и объективность, подтвержденные исследователями данных.
Для реализации модели распознавания дорожных знаков был выбран набор данных RTSD [21], который предназначен для качественного обучения и тестирования алгоритмов распознавания дорожных знаков. Этот набор разработан исследовательской командой в составе А. Конушина и В. Шахуро для решения ряда задач: уменьшить количество ложных срабатываний прогностических моделей при их обучении и дальнейшей работе, повысить точность распознавания моделей [21].
Набор данных RTSD содержит 179 138 кадров с 104 358 изображениями знаков. Общее количество уникальных знаков – 156 [21]. Согласно анализу, проведенному авторами статьи [21], набор данных превосходит другие публичные базы дорожных знаков по множеству характеристик, включая количество кадров, физических знаков, классов знаков, их изображений. Немаловажным преимуществом набора данных является наличие в нем изображений знаков в разное время суток, года, в разных погодных условиях.
За основу при составлении обучающей и тестовой выборки взято публичное представление набора RTSD, предназначенное для задачи обнаружения [22]. Набор содержит 47 639 изображений с 80 277 знаками в тренировочной выборке и 11 389 изображений с 25 232 знаками в тестовой выборке.
Для осуществления возможности проведения множества экспериментов по сборке модели было решено сузить набор до 1 842 изображений на обучающей выборке и 493 на тестовой выборке путем взвешенного отбора знаков всего набора путем исключения условно повторяющихся изображений одного участка. Общее число классов составило 146. Полученный набор классов представлен на рис. 1.

Рис. 1. Набор классов обучающей выборки
Fig. 1. A set of training sample classes
Модель распознавания дорожных знаков российского образца
Как упоминалось выше, основным инструментом для создания модели выбрана модель из семейства YOLO – YOLOv7. Базовые модели семейства YOLO обучались на наборе данных MS COCO, составляющем 330 000 изображений с более чем 1,5 млн размеченных объектов.
Поскольку элементы группы моделей YOLOv7 являются трансферными моделями, сама модель в процессе обучения не претерпевает кардинальных изменений: она сохраняет свою общую структуру и архитектуру, но ее параметры настраиваются на основе новых данных и новой задачи. Этот процесс позволяет модели быстро адаптироваться к новым сценариям и улучшать свою способность к распознаванию и классификации объектов.
Архитектура группы моделей YOLOv7 [19] приведена на рис. 2.
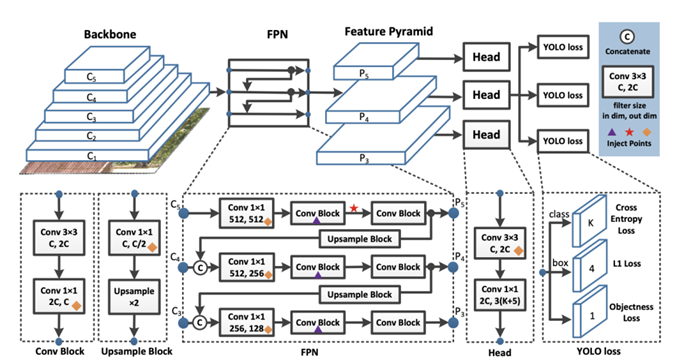
Рис. 2. Архитектура группы моделей YOLOv7
Fig. 2. The architecture of the YOLOv7 model group
Для обучения нейронной сети на основе YOLOv7 данные были разделены в соответствии с описанием структуры тестового и обучающего набора данных YOLOv7. Среди семейства сверточных моделей YOLOv7 для дальнейшего дообучения требованиям задачи отвечают две: YOLOv7 и YOLOv7-tiny, т. к. позволяют быстро и с высокой точностью распознавать объекты на изображении согласно документации YOLOv7.
YOLOv7 – это полноразмерная модель, которая обладает большим количеством слоев и параметров. Она предназначена для высокоточного обнаружения объектов, но требует больше вычислительных ресурсов и памяти. YOLOv7-tiny является уменьшенной версией модели. Она имеет меньше слоев и параметров, что делает ее более легкой и быстрой, но менее точной в сравнении с YOLOv7. YOLOv7-tiny предоставляет баланс между скоростью обработки и точностью обнаружения [19].
В архитектуре моделей учитывается 31 указанный в явном виде гиперпараметр. Был осуществлен подбор наиболее важных гиперпараметров: momentum и weight_decay, отвечающих за изменение скорости и параметров модели, установленных в значении 0,936 и 0,00055 соответственно; learning rate – lr0 и lrf, отвечающих за скорость обучения, адаптации модели к новым данным, установлены в 0,01 и 0,2 соответственно. Произведено изменение размера изображения до 1 920 × 1 080 в случае несоответствия заданному размеру. Проведенные эксперименты показали, что увеличение размера изображения приводит к улучшению качества модели, но существенно увеличивает время обучения. В YOLOv7 имеются автоматические методы оптимизации для упрощения подбора гиперпараметров.
Проведен анализ результатов обучения базовых моделей YOLOv7 и YOLOv7-tiny. Анализ проводился на промежуточных этапах каждые 50 эпох, а также общий анализ после 250 эпох. Лучший результат за меньшее время получен с использованием модели YOLOv7-tiny (mAP@.5 – 0,393 за 0,93 ч по сравнению с mAP@.5 – 0,339 при обучении модели YOLOv7 в течение 3 ч), поэтому было принято решение выбрать модель YOLOv7-tiny.
Процесс дальнейшего дообучения и выход на плато обучения позволил получить модель, которая удовлетворяет требованиям качества согласно определенным метрикам: усредненная точность mAP@.5 – 0,884; точность предсказаний precision – 0,847.
Согласно матрице ошибок, представленной на рис. 3, число ячеек, отклоняющихся от главной диагонали, незначительно, что также свидетельствует о корректности модели.
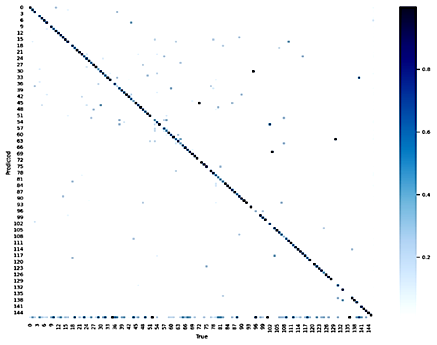
Рис. 3. Матрица ошибок для созданной модели
Fig. 3. Error matrix for the created model
Таким образом, процесс создания модели состоял из следующих этапов: загрузка предварительно обученной модели, подбор гиперпараметров, обучение на пользовательском наборе данных, оценка и настройка модели, дообучение.
Модель была протестирована на тестовых данных, полученных из сети. Визуальный анализ показал, что распознавание объектов на изображениях и классификация дорожных знаков проводятся корректно. Корректны как обозначение рамки, так и обозначение класса знака. Пример вывода предсказаний сформированной модели представлен на рис. 4 (на фотографии найдены знаки и указаны коды их классов согласно ГОСТ Р 52290-2004).

Рис. 4. Пример работы модели
Fig. 4. An example of how the model works
Разработанная модель (набор весов) выложена на облачном сервисе drive [23]. Это позволит использовать ее исследователям в области создания моделей распознавания.
Заключение
Разработана модель в виде сверточной нейронной сети для распознавания дорожных знаков, способная выделять и классифицировать знаки российского образца в видеопотоке или на статичных изображениях, отличающаяся от известного высоким уровнем точности на объемной тестовой выборке. Особенности обучения и тестирования модели позволяют утверждать, что модель распознает знаки в разное время года, суток и в разных погодных условиях.
Модель можно использовать в экспериментальном программном комплексе, нацеленном на создание беспилотного средства, системы помощи водителю. У модели имеются перспективы развития, в том числе в направлении улучшения точности.
Разработанная прогностическая модель может послужить опытным образцом для проведения первых экспериментов по обучению и валидации прогностической модели для начинающих исследователей в области распознавания российских дорожных знаков.
1. Юрин И. В., Лебедев Г. В., Лившиц И. И. Перспективы использования безэкипажных транспортных судов в морях арктического бассейна России // Науч.-техн. вестн. информац. технологий, механики и оптики. 2021. № 1. С. 73–84.
2. Дремлюга Р. И., Крипакова А. В., Яковенко А. А. Регулирование тестирования и использования беспилотного автотранспорта: опыт США // Журн. зарубеж. законодательства и сравнит. правоведения. 2020. № 3. C. 68–85.
3. Короткова Ю. А. Особенности восприятия информации водителем высокоавтоматизированного транспортного средства // Безопасность дорожного движения. 2022. № 3. C. 48–51.
4. Акатьев Я. А., Латыпов А. Р. Анализ особенностей алгоритмов машинного обучения в автоматизированных системах вождения // E-Scio. 2022. № 1 (64). C. 641–655.
5. Kshitij Dhawan, Srinivasa Perumal R., Nadesh R. K. Identification of traffic signs for advanced driving assistance systems in smart cities using deep learning // Multimedia Tools and Applications. 2023. V. 82. P. 26465–26480.
6. Енокаев Р. М. Алгоритм распознавания дорожных знаков // Прикладная математика: современные проблемы математики, информатики и моделирования. 2020. № 2. C. 113–117.
7. Гильманов Т. А. Система распознавания дорожных знаков // Science Time. 2014. № 8 (8). C. 80–85.
8. Медведев М. В., Кирпичников А. П., Синичкина Т. А. Детектирование дорожных знаков при помощи компьютерного зрения // Вестн. Казан. технолог. ун-та. 2016. Т. 19. № 18. С. 143–147.
9. Никитин Д. В., Тараненко И. С., Катаев А. В. Детектирование дорожных знаков на основе нейросетевой модели YOLO // Инженер. вестн. Дона. 2023. № 7 (103). C. 91–99.
10. Стахеева А. А., Крайников А. Н., Вяткин Д. А. Распознавание дорожных знаков с использованием сверточной нейронной сети // Междунар. журн. приклад. наук и технологий «Integral». 2023. № 4. С. 1277–1300.
11. Кузнецова А. П. История дорожных знаков // САПР и ГИС автомобильных дорог. 2014. № 1 (2). C. 99–104.
12. ГОСТ Р 52290-2004. Технические средства организации дорожного движения. Знаки дорожные. Общие технические требования. М.: Стандартинформ, 2006. 126 с.
13. Кривопалов А. Д., Скворцов А. В., Петренко Д. А. Использование различных стандартов при описании дорожных данных в программных продуктах «ИндорСофт» // САПР и ГИС автомобильных дорог. 2014. № 1 (2). C. 87–89.
14. Харченко И. К., Боровской И. Г., Шельмина Е. А. Использование ансамбля сверточных нейронных сетей для распознавания дорожных знаков // Вестн. Томск. гос. ун-та. Управление, вычислительная техника и информатика. 2022. № 61. C. 88–96.
15. Николенко С., Кадурин А., Архангельская Е. Глубокое обучение. Погружение в мир нейронных сетей. СПб.: Питер, 2018. 480 с.
16. Алексеев П., Квятковская И. Ю. Применение нейронных сетей для распознавания принципиальных условно-графических электрических обозначений // Вестн. Астрахан. гос. техн. ун-та. Сер.: Управление, вычислительная техника и информатика. 2021. № 2. С. 47–56.
17. Андриянов Н. А., Дементьев В. Е., Ташлинский А. Г. Обнаружение объектов на изображении: от критериев Байеса и Неймана – Пирсона к детекторам на базе нейронных сетей EfficientDet // Компьютерная оптика. 2022. Т. 46. № 1. С. 139–159.
18. Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg SSD: Single Shot MultiBox Detector // Computer Vision and Pattern Recognition. URL: https://arxiv.org/abs/1512.02325 (дата обращения: 26.09.2023).
19. Chien-Yao Wang, Bochkovskiy A., Hong-Yuan Mark Liao. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors // Computer Vision and Pattern Recognition. URL: https://arxiv.org/abs/2207.02696 (дата обращения: 27.09.2023).
20. Болховитина Е. И. Исследование моделей сверточных нейронных сетей YOLOv3 и retinanet для задачи детектирования лица человека на изображении // StudNet. 2022. Т. 5. № 6. С. 5439–5448.
21. Шахуро В. И., Конушин А. С. Российская база изображений автодорожных знаков // Компьютерная оптика. 2016. Т. 40. № 2. С. 294–300. DOI:https://doi.org/10.18287/2412-6179-2016-40-2-294-300.
22. Конушин А. С. Набор данных RTSD. URL: https://graphics.cs.msu.ru/projects/traffic-sign-recognition.html (дата обращения: 05.09.2023).
23. Солопекин Д. А. Веса лучшей модели. URL: https://drive.google.com/file/d/1xmHbaJ6vW6-dgrhss_tZH7lFrrrbyY3Y/view?usp=sharing (дата обращения: 13.10.2023).
